
环境准备
- Ubuntu 虚拟机/VPS
建议在Ubuntu上配置调试环境,便于后续GDB+pwndbg 调试。
配置环境
安装编译与运行依赖
apt update && apt install -y \
build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm \
libncurses5-dev libncursesw5-dev xz-utils tk-dev \
libffi-dev liblzma-dev libnss3-dev uuid-dev \
libgmp-dev autoconf bison libyaml-dev \
libgdbm-dev libdb-dev libgdbm-compat-dev lrzsz \
python-openssl git gdb gcc-multilib
# 启用32位兼容运行环境
dpkg --add-architecture i386
apt update && apt install -y libc6:i386 lib32z1
安装 Python 虚拟环境
curl https://pyenv.run | bash
# 添加环境变量 ~/.bashrc 或 ~/.zshrc
export PATH="$HOME/.pyenv/bin:$PATH"
eval "$(pyenv init --path)"
eval "$(pyenv init -)"
source ~/.bashrc
pyenv install 3.9.5
pyenv virtualenv 3.9.5 pwnenv
pyenv activate pwnenv
安装 Ruby + PWN 辅助工具
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
export PATH="$HOME/.rbenv/bin:$PATH"
eval "$(rbenv init -)"
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
rbenv install 3.2.6
rbenv global 3.2.6
gem install one_gadget seccomp-tools
什么是PWN?
PWN 原指“own”(控制、攻破)的俚语变体,最初出现在黑客文化中。后被 CTF(Capture The Flag)竞赛广泛使用,用来指代利用程序二进制漏洞实现控制、提权、信息泄露等攻击手段的一类题型。
PWN ≈ 利用二进制程序漏洞控制程序流程
核心手段:栈溢出、格式化字符串、堆溢出、UAF、整数溢出等
最终目标:执行恶意代码或泄露敏感数据
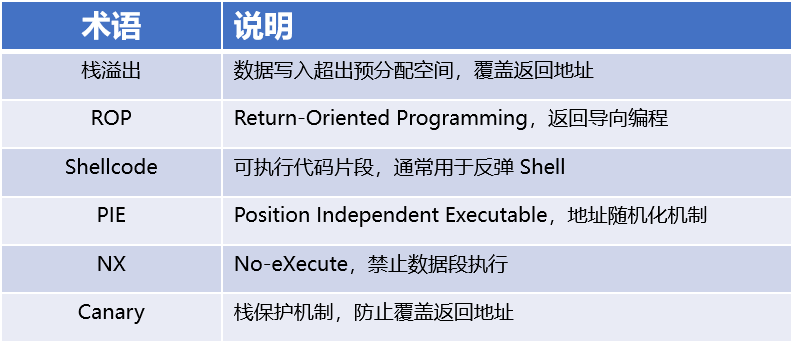
常见术语
现在不懂没关系,不需要有压力,当作了解即可
程序如何来的?
我们知道计算机的可执行程序是通过编译器编译出来的,但是我们并不了解它更深层次的相关内容。
他的大致流程如下图:高级语言(比如C语言) -> 汇编代码 -> 机器码(二进制数据) -> 可执行程序
其中,编译器(如gcc)将高级语言编译成汇编语言,汇编器和链接器将这些内容变为二进制的可执行文件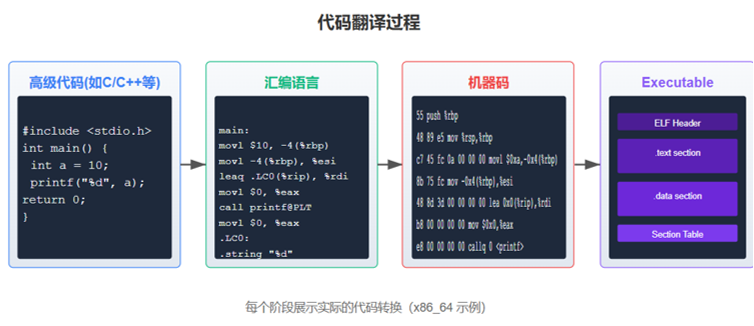
可执行文件类型
我们最常见的可执行文件无非就是Windows平台上的exe程序了,除了这种,还有哪些呢?
Windows
- .dll:动态链接库
- .lib:静态链接库
- .exe:可执行文件
Linux
- .so:动态链接库
- .a:静态链接库
- .out(或无后缀):可执行文件
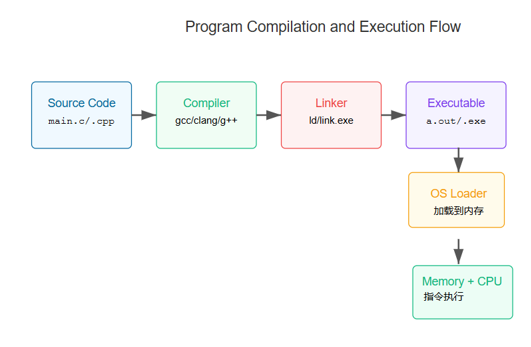
程序运行原理
程序从硬盘加载进内存后,由操作系统将控制权交给程序入口点(如 _start ),然后开始执行。
这个_start 等会就会提到,一般程序的入口点都是这个_start 。
第一个程序分析实践
使用一个简单的 test.c ,结合 objdump 反汇编,观察编译后的机器码结构。
#include <stdio.h>
int main(){
int a=10;
int b=20;
int c=a+b;
printf("%d+%d=%d\n", a, b, c);
return 0;
}
编译32位可执行程序
gcc -m32 test.c -o test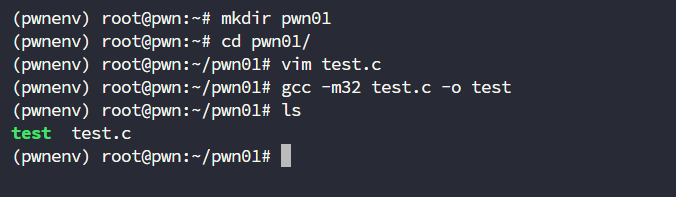
通过objdump查看反汇编
objdump -d test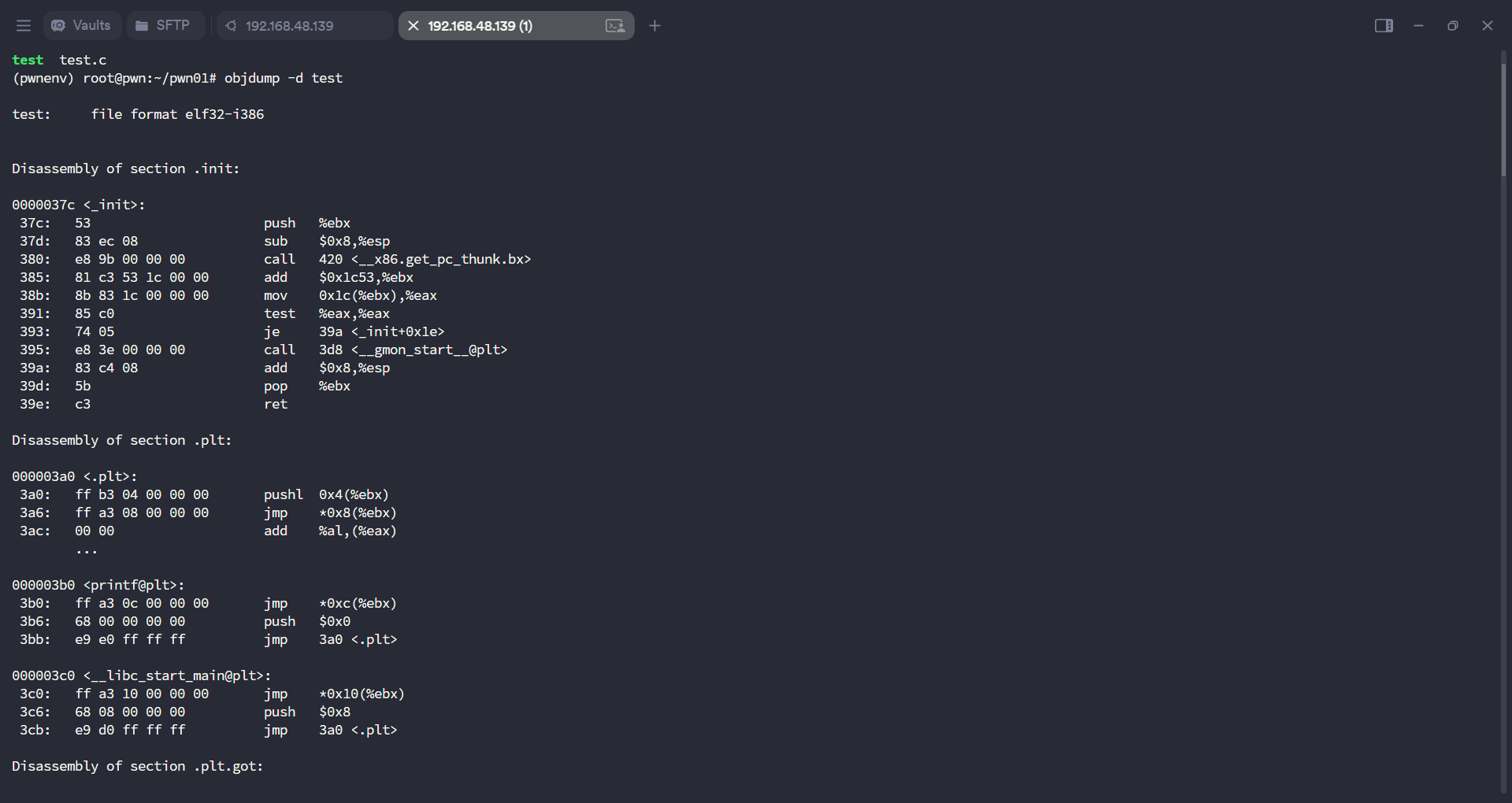
如果没有汇编的基础的话,你会发现这啥玩意,完全看不懂,没关系,接下来就一步一步来了解
关键观察点
- .text 段:代码逻辑部分,包含main
- .plt/.got :动态链接跳转表,涉及函数调用如 printf
_start-> main :程序的入口跳转关系- call:调用函数
- add:两数相加
- mov:类似于赋值的意思

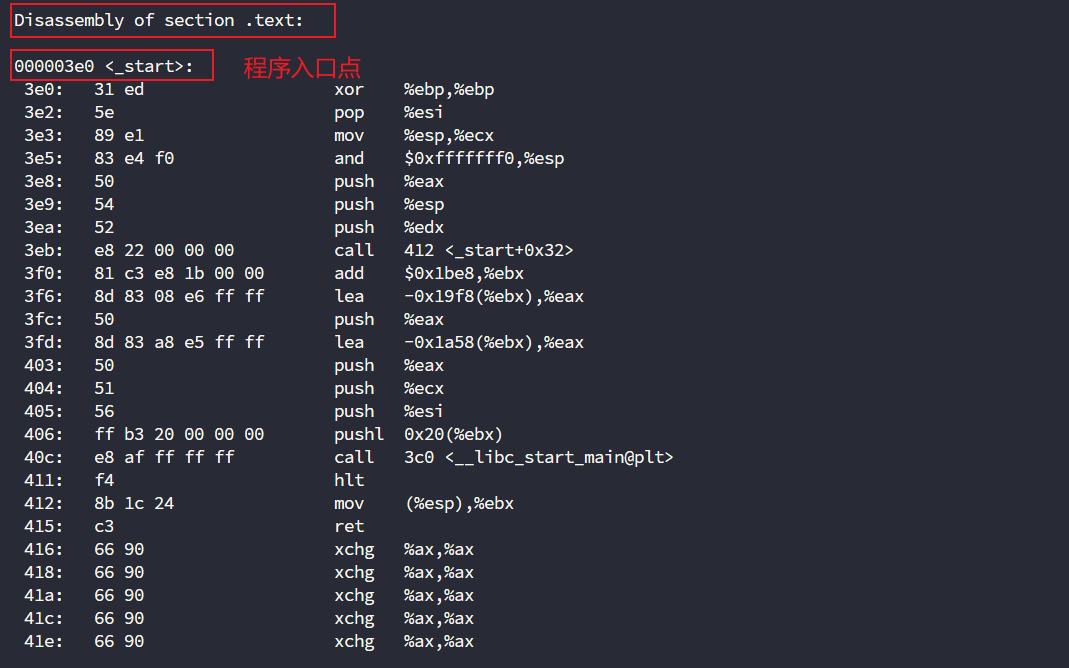
在 C 语言中,我们习惯将 main 视为程序入口,但实际上:
- 操作系统加载 ELF 可执行文件后,会首先跳转到
_start符号(对应汇编中的000003e0 <_start>),这是链接器(ld)默认设置的入口点。 _start的核心任务是:初始化运行环境(如栈对齐)、准备main的参数,最终调用__libc_start_main(C 标准库函数),由它间接启动main。
这里面从__libc_start_main转到main比较复杂,所以我们先默认调用__libc_start_main即为转到main
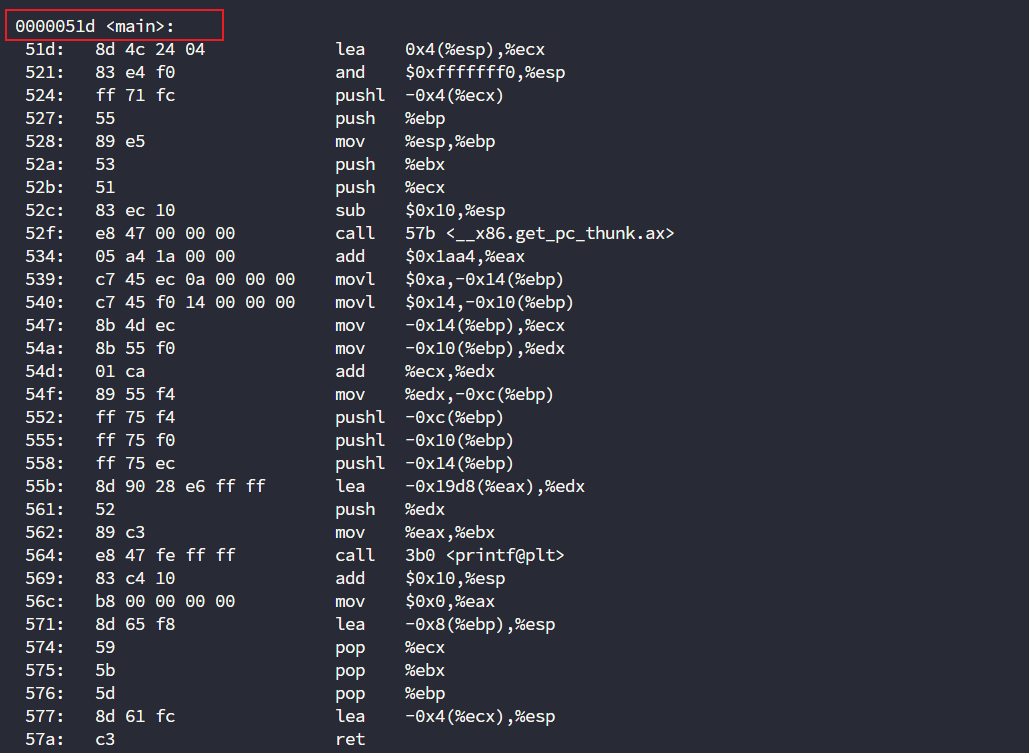
这时候我们观察一下mian函数的整体,发现基本都是我们看不懂的汇编代码,不过还是有几个入手的地方的
比如说printf应该就是调用printf函数的,那么在两数相加应该就在printf之前了
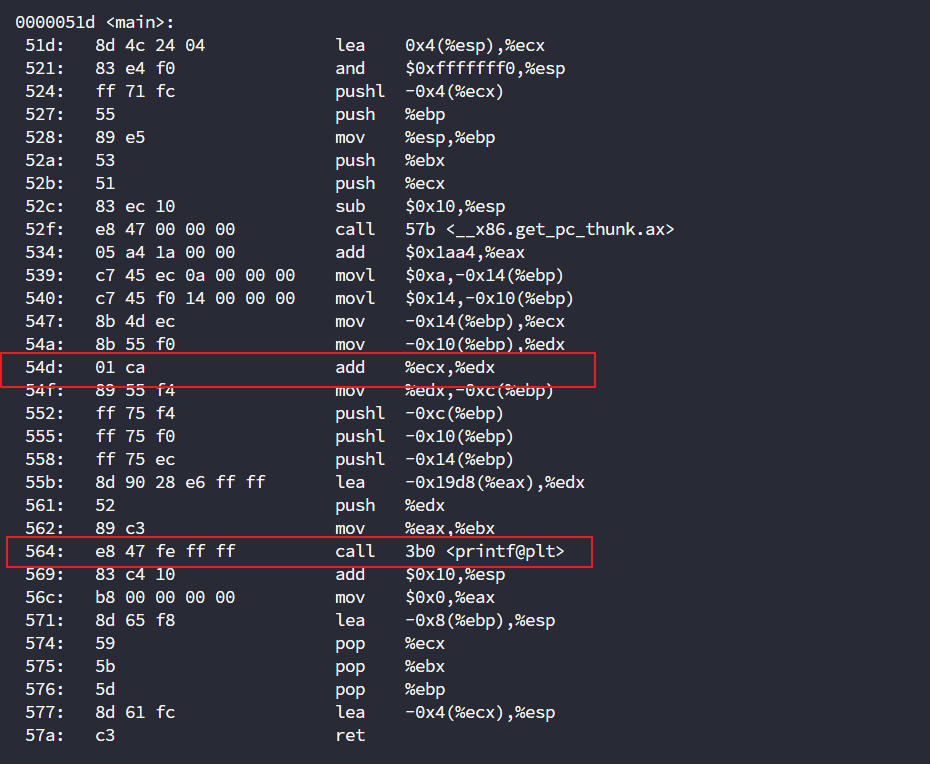
那么ecx和edx基本就是10和20了,那到底谁才是10和20呢?
继续向前观察发现存在mov赋值
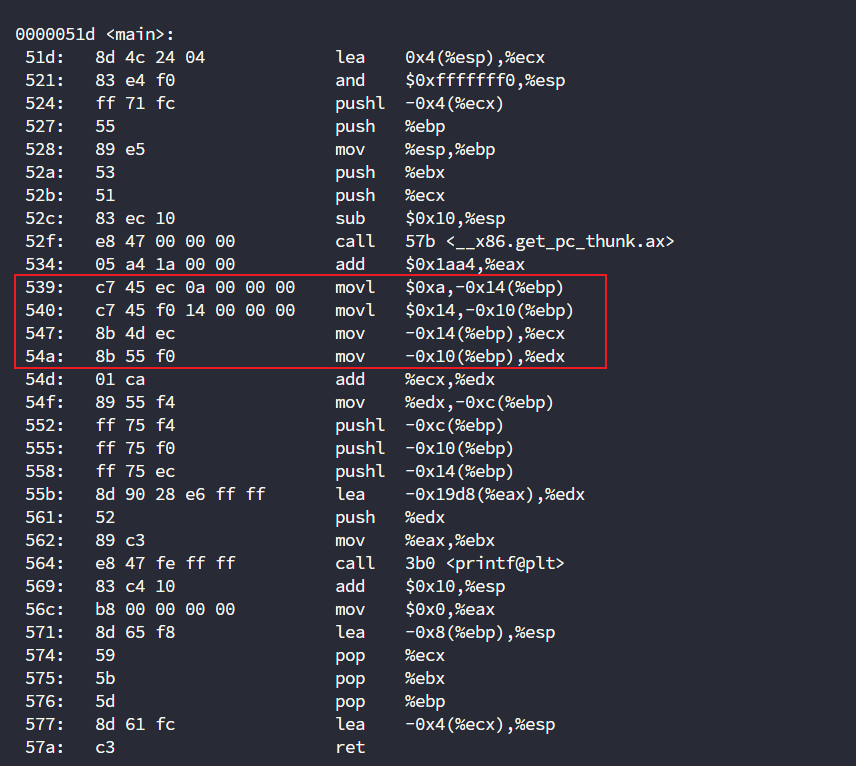
在我们看不懂的情况下,我们要知道谁是10,谁是20其实很简单,10=0xa,20=0x14。
现在其实就很明显了,10被赋值到-0x14(%ebp)这个地方,然后-0x14(%ebp)又被赋值给了%ecx,所以%ecx就是10,那么另一个%edx就是20了
那现在其实我们就基本捋清楚脉络了,但是上面的内容都是我们自己的猜测,接下来我们得去验证我们的猜测
GDB调试分析验证猜测
在Linux中,可以采用的调试工具有好几个,但是这次我们采用GDB这个工具来帮助我们进行调试
输入help可以查看帮助命令,但是命令并不是全部,需要全部命令的话得自己去看文档
https://linuxtools-rst.readthedocs.io/zh-cn/latest/tool/gdb.html
调试
gdb test # 调试可执行程序
run # 直接运行
break main # 在main函数处下断点
可以看到已经成功停到这个断点的地方了,我们可以查看对应的反汇编来确认
disassemble main # 查看指定函数的汇编代码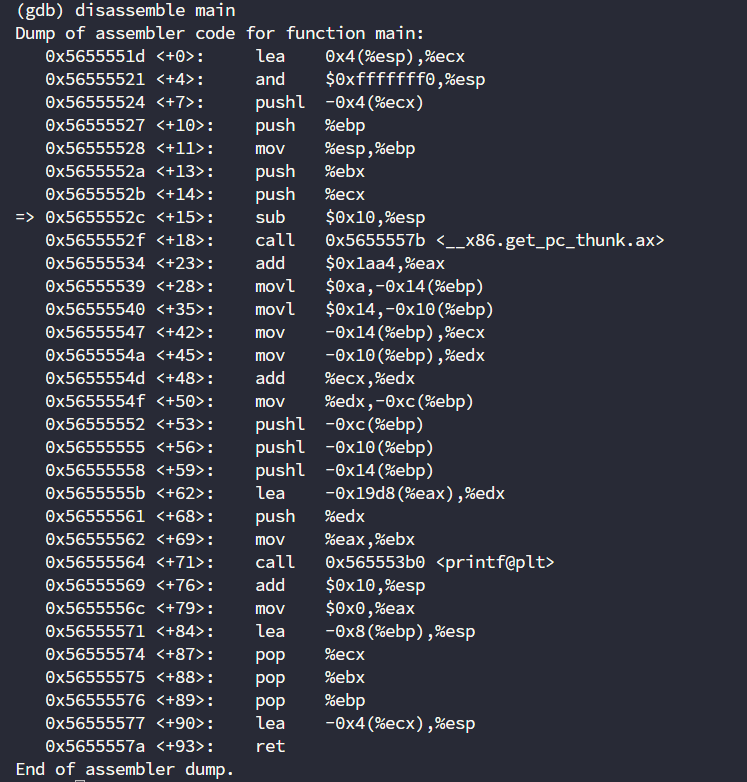
基本一致,说明我们这时候确实到了main函数这个位置
到了main函数的位置,那么我们就得确定我们之前的猜测是否正确了,先下断点到哪呢?
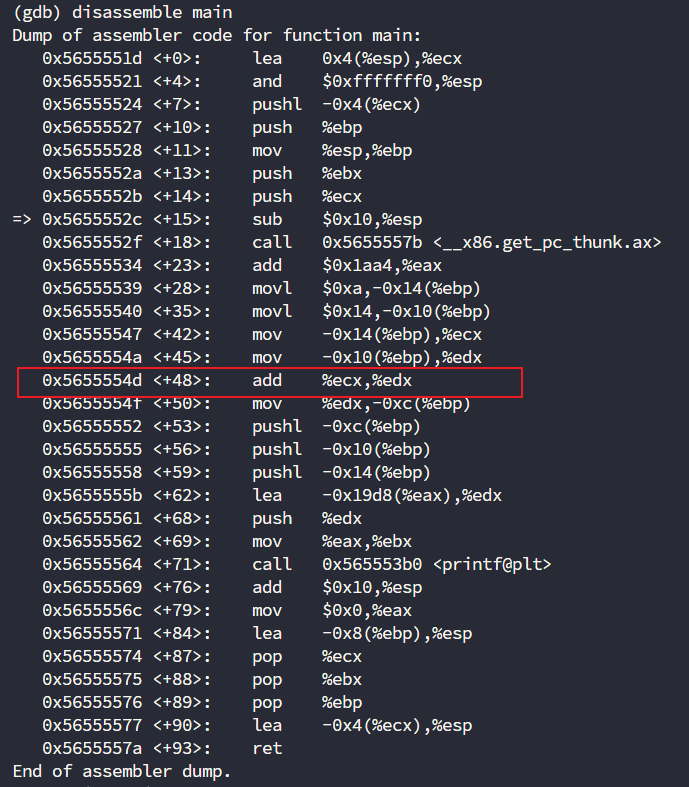
先下断点到这个地址,我们先看看ecx是否真的为10,edx是否真的为20
break *main+48 # 在对应偏移下断点
next # 继续运行到下一个断点,可以简写为n
info register ecx # 打印寄存器ecx的值,可以简写为i r ecx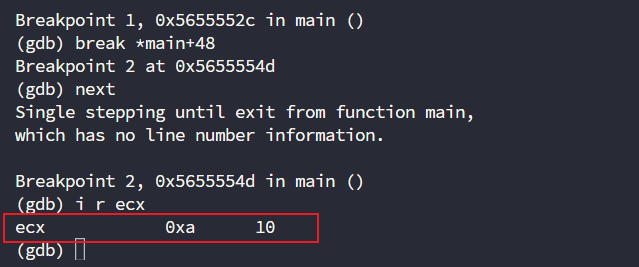
可以看到确实为10,edx也确实是20
那么我们去下另一个位置的断点,来看看-0x14(%ebp)是否为10呢?
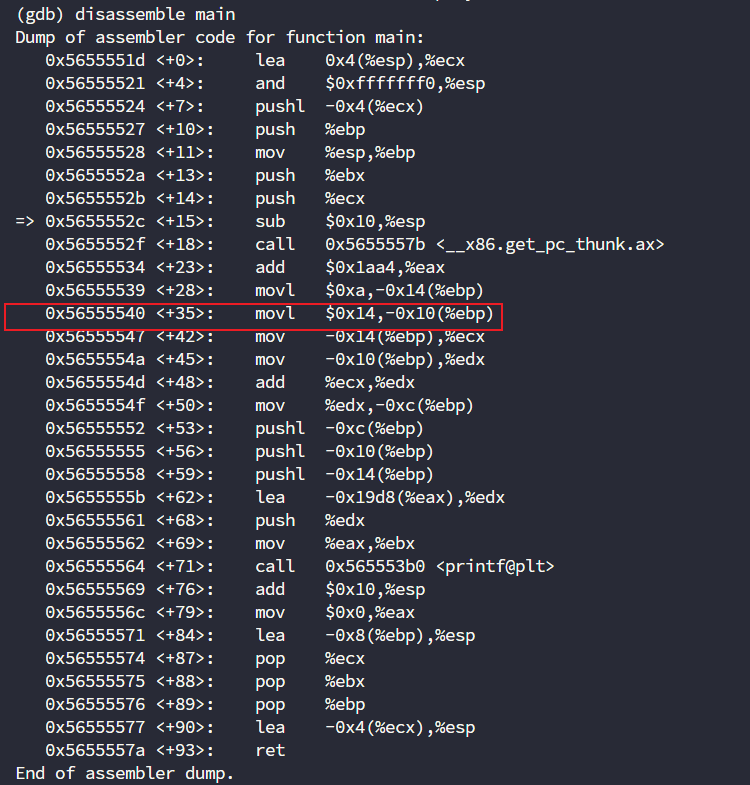
break *main+35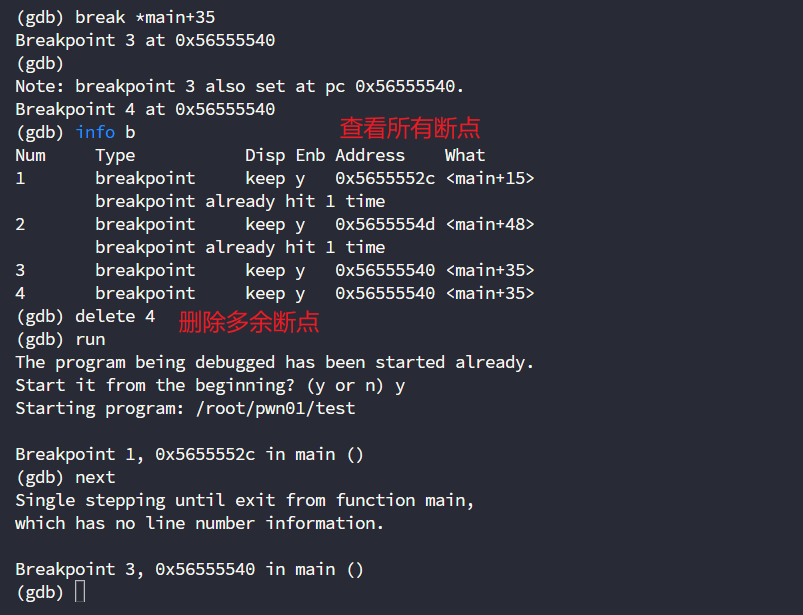
x/i $pc # 查看当前行的指令
x/d $ebp-0x14 # 十进制查看内存单元的值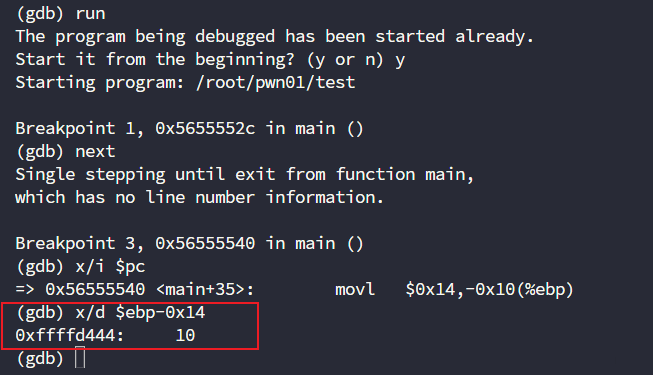
x 命令(检查内存)支持多种格式,格式符如下:
d:十进制x:十六进制(默认)u:无符号十进制s:字符串c:字符
此时我们基本能验证,我们上面的猜测是正确的了,但是别忘了,我们学习这些知识是为了什么?
为了pwn,所以我们至少得改点东西意思意思
值修改
修改哪个地方呢?在ecx和edx相加之前修改吗?我们可以尝试一下
set $ecx = 800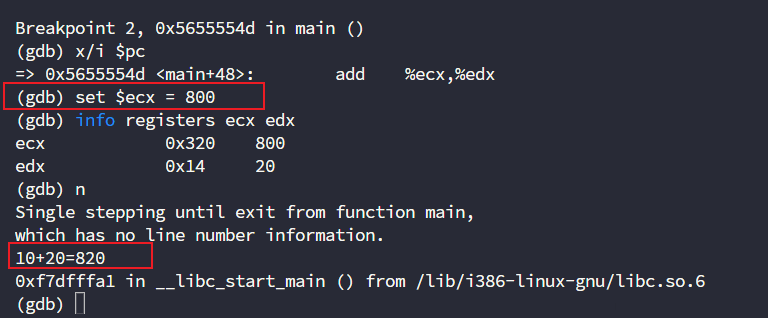
我们确实成功修改了ecx的值,但是输出不正确啊,这是为啥?
我们知道函数调用的参数需要压入栈中调用,观察红色第一部分,可以发现edx被存到-0xc(%ebp)中,接下来就和-0x10(%ebp)、-0x14(%ebp)一起被push进栈中,所以这时候结果正确,但是表达式不正确,因为-0x10(%ebp)、-0x14(%ebp)这俩我们没改到
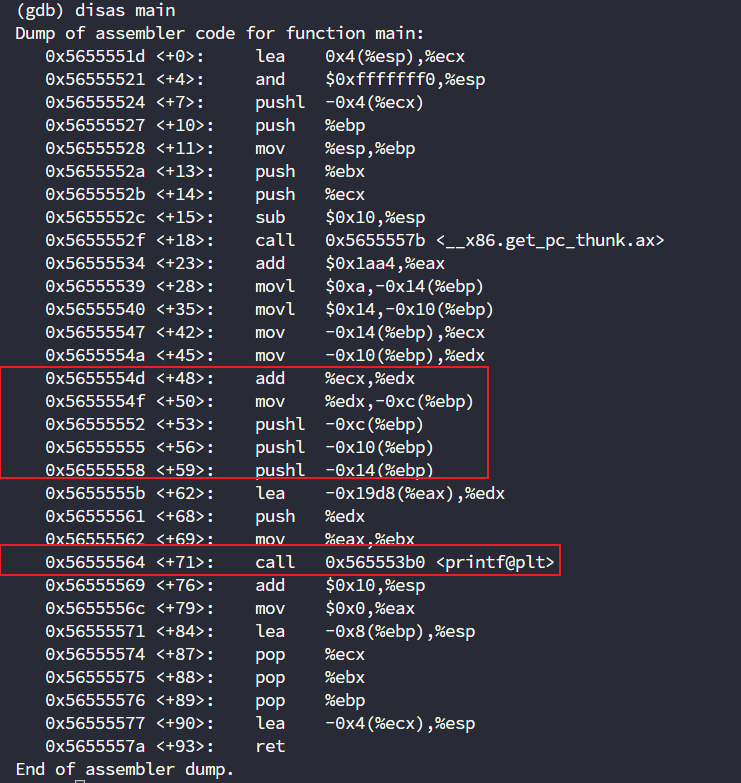
那么知道什么地方错了之后,我们就可以针对性进行修改了,我们知道要从源头开始修改,所以,我们要改的地方就是-0x14(%ebp)
set *(int*)($ebp-0x14) = 800(int*):将上述地址强制转换为 “指向 int 类型的指针”(告诉 GDB 该地址存储的是 int 数据)。*:解引用指针,即访问该指针指向的内存单元(获取或修改该地址存储的实际值)。
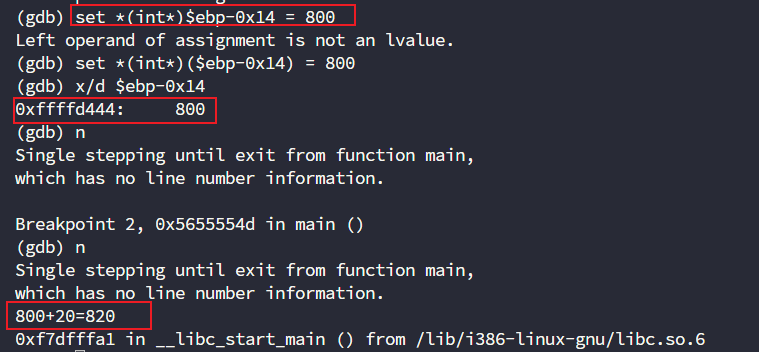
至此修改成功
将输出换成其他字符串
既然我们可以修改传入栈中的值,那么我们能否改变printf输出的字符串呢?
先看一个例子
def printf(a, b):
print(a, b)可以看到这个函数会传入参数,而参数就是通过push到栈传递的,同时他是先进后出
push a
push b
call printf这时候就是printf(b, a)
那么我们的源程序是printf("%d+%d=%d\n", a, b, c),这时候我们只要找到"%d+%d=%d\n"这个参数就行了
一共是4个参数,根据先进后出的原则,基本可以确定就是
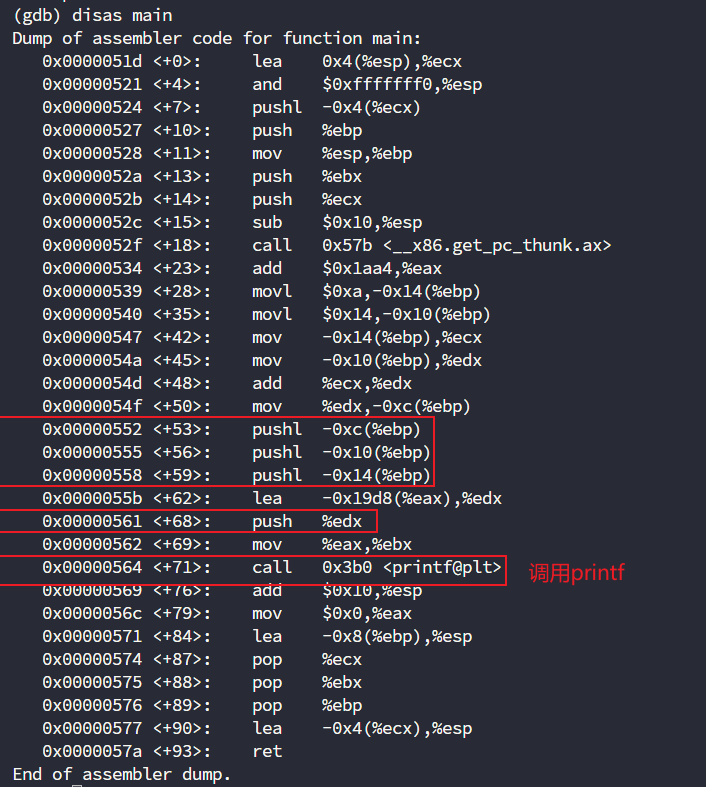
定位到这里
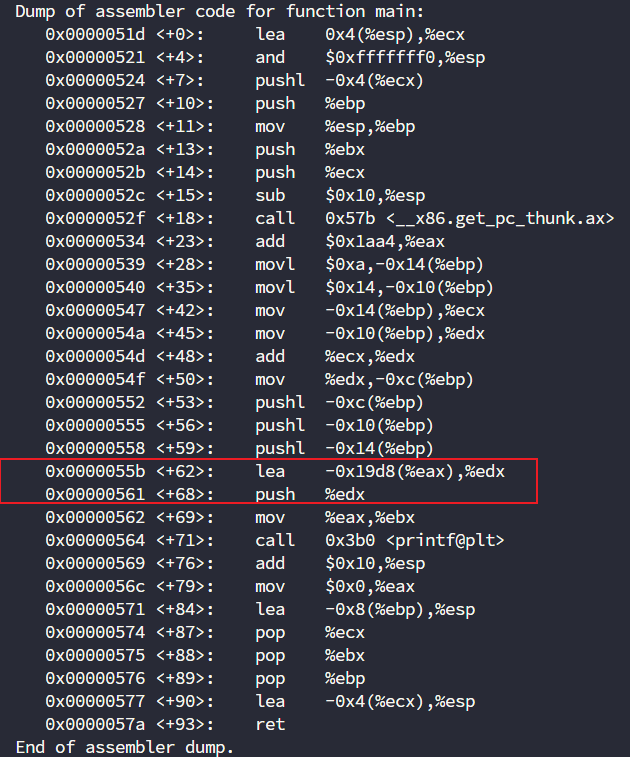
基本可以定位是edx了,但是注意上一段代码,edx是从eax的某个偏移内存地址获取到的,所以我们要从源头出发进行修改
lea -0x19d8(%eax),%edx
; edx = eax - 0x19d8 等价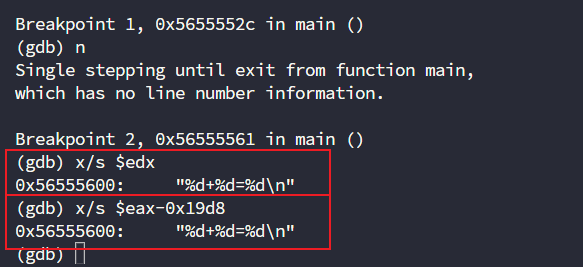
set {char[14]}($eax-0x19d8) = "Hello World!\n"
# char数组要计算出字符串的位数,记得还得算上末尾的\0一位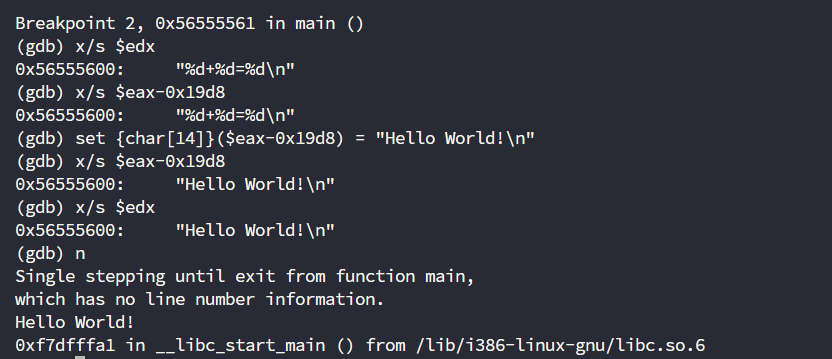
此时就已经成功修改了
system执行替换
既然上面我们已经学会了如何替换传入的参数,那么如果我们的代码变成这样呢?
#include <stdio.h>
#include <stdlib.h>
int main(){
int a=10;
int b=20;
int c=a+b;
printf("%d+%d=%d\n", a, b, c);
system("whoami");
return 0;
}那是不是我们只要分析出来system传入的是哪个参数,我们就可以实现任意的命令执行?
gcc -m32 test2.c -o test2
objdump -d test2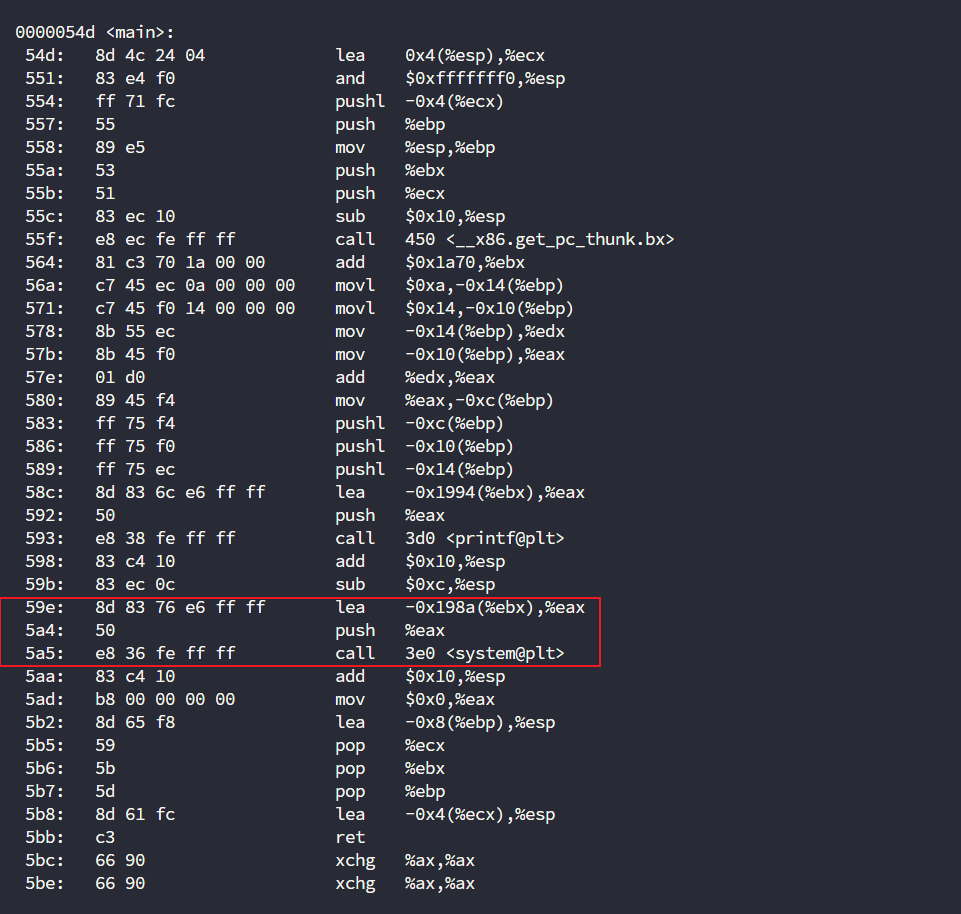
定位到此处之后,我们可以发现对应传入的字符串地址
通过gdb进行动态调试
break main
break *main+87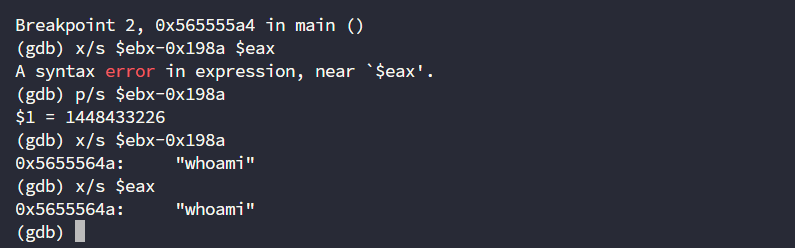
接下来直接修改对应的源地址$ebx-0x198a即可
set {char[3]}($ebx-0x198a)="id"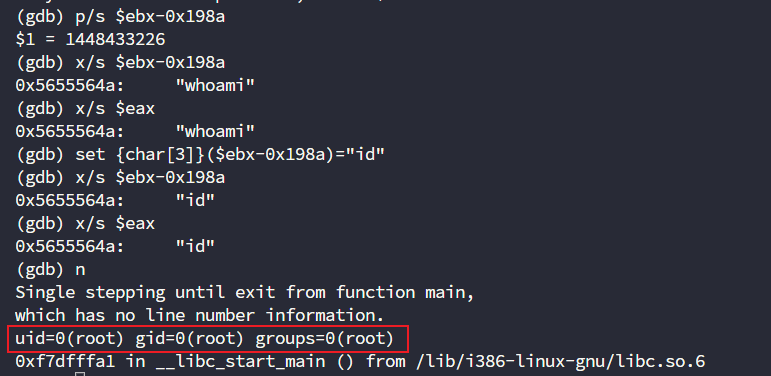
无system函数调用
那么当我们回到最初的代码,我们还能调用system来实现命令执行吗?
#include <stdio.h>
int main(){
int a=10;
int b=20;
int c=a+b;
printf("%d+%d=%d\n", a, b, c);
return 0;
}先在main函数处打上断点,然后run到main函数处暂停(如果不这么做的话,因为system函数在libc中,而libc是程序运行时才动态加载的,不运行查看不到)
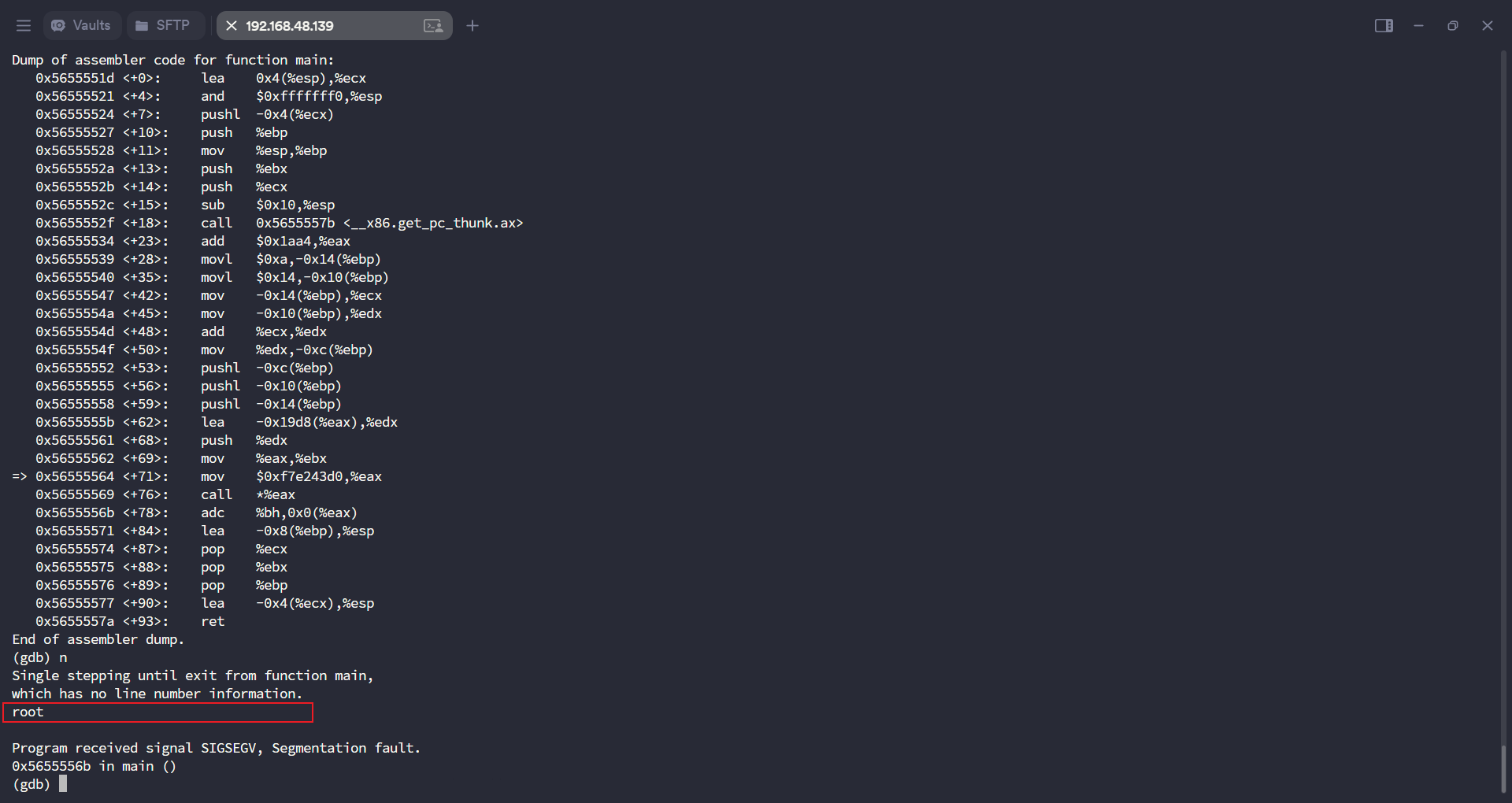
此时查看system函数的内存地址
info functions system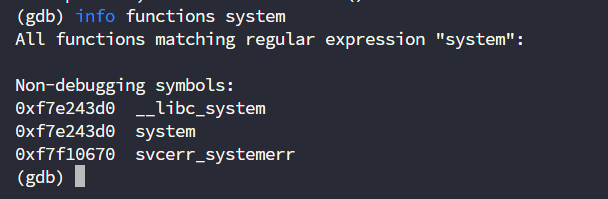
此时我们已经得到了system函数的地址,这时候我们只需要将要执行的命令以及call的地址进行替换即可
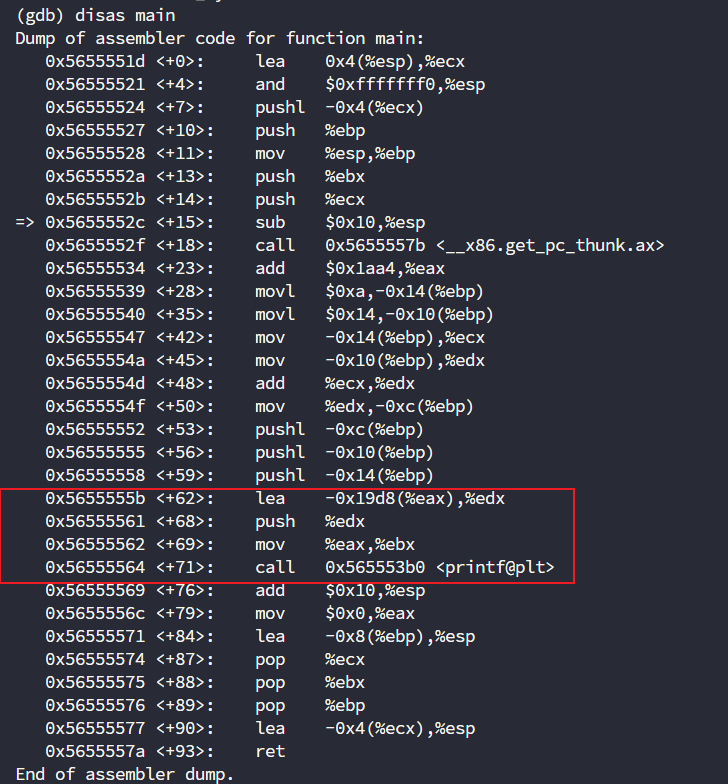
要执行的命令替换很简单,直接断点打到+68的偏移,然后将eax-0x19d8的内容修改即可
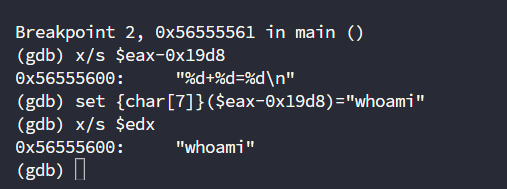
替换call的地址为system函数的地址0xf7e243d0
set {char[5]}0x56555564={0xe8,0xd0,0x43,0xe2,0xf7}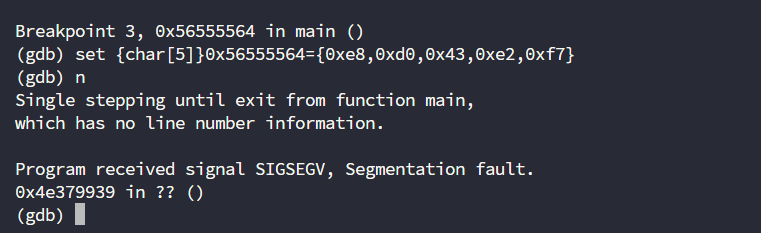
发现程序无法正常运行,看起来我们没法直接调用system函数的地址,但是经过之前几次的尝试,我们其实发现了寄存器eax、edx他们都能存储地址,如果我们将system函数的地址存储在寄存器中,再去call寄存器呢?
set {char[7]} 0x56555564 = {0xb8,0xd0,0x43,0xe2,0xf7,0xff,0xd0}
可以看到对应输入的二进制会对应到汇编代码为
0xb8,0xd0,0x43,0xe2,0xf7 ==> mov $0xf7e243d0,%eax
0xff,0xd0 ==> call *%eax0xb8,0xd0,0x43,0xe2,0xf7 对应 mov $0xf7e243d0,%eax
- 操作码(第 1 字节
0xb8):
x86 指令集中,0xb8是专门用于 “将 32 位立即数传送到eax寄存器” 的操作码,格式为:
0xb8 + 4字节立即数→mov $立即数, %eax 立即数(后 4 字节
0xd0,0x43,0xe2,0xf7):
这 4 字节按 小端字节序 存储,转换为 32 位数值为0xf7e243d0:- 小端字节序要求 “低字节存低地址”,因此内存中
0xd0(低字节),0x43,0xe2,0xf7(高字节)对应的数值是0xf7e243d0。
- 小端字节序要求 “低字节存低地址”,因此内存中
- 完整对应:
0xb8(操作码) + 0xd0,0x43,0xe2,0xf7(立即数)→ 汇编为mov $0xf7e243d0, %eax,即 “将0xf7e243d0写入eax寄存器”。
0xff,0xd0 对应 call *%eax
- 操作码(第 1 字节
0xff):
0xff是 x86 中的 “通用操作码”,具体功能由第 2 字节(ModR/M 字节)决定,可表示 “调用、跳转、加 1” 等操作。 ModR/M 字节(第 2 字节
0xd0):
ModR/M 字节是 x86 指令中用于指定操作数(寄存器或内存)的编码,0xd0的二进制是11010000,拆分后:- 高 2 位(
11):表示 “操作数是寄存器(而非内存)”; - 中间 3 位(
010):表示 “寄存器编号 2”(对应eax,x86 寄存器编码中eax对应编号 0,但此处因特殊编码); - 低 3 位(
000):配合0xff操作码,表示 “调用(call)” 操作。
- 高 2 位(
- 完整对应:
0xff(操作码) + 0xd0(ModR/M 字节)→ 汇编为call *%eax,即 “间接调用eax寄存器指向的地址”。
最终成功实现命令执行
疑问
- 为什么不调用
system函数,不包含stdlib.h也可以实现system函数的调用执行呢?
程序动态链接 libc 时,整个 libc 库(包含其中的所有函数,如 printf、system 等)会被映射到进程内存中,无论程序是否显式调用这些函数。因此,只要 libc 被动态链接(默认情况如此),即使程序没包含任何头文件,也能通过地址直接调用 system 函数(例如汇编层面的 call 指令)。
printf 和 system 都是 libc 的一部分,动态链接 libc 是整体加载该库,而非只加载被调用的函数。
因此,只要 `printf` 能被调用(说明 `libc` 已动态链接),`system` 必然存在于进程内存中,理论上可被调用。
头文件(如 stdlib.h)仅影响编译阶段的语法检查,与运行时 system 是否存在于内存无关。
当然了,如果你编译的时候选择静态编译的话,那么只会导入程序需要的东西,那样就不会导入system了
gcc -m32 --static test.c -o test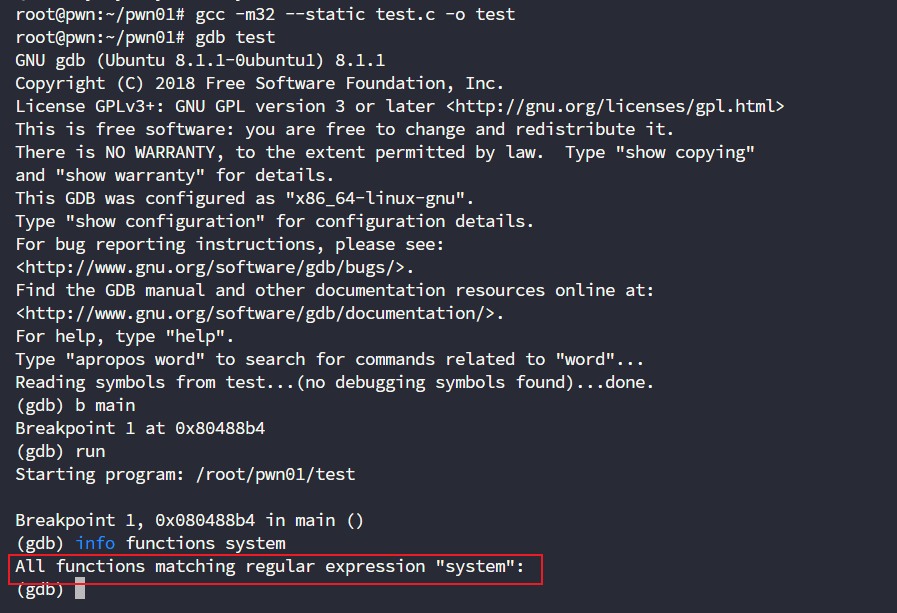

评论 (0)